Elastic Stack Fleet 服务器配置指南(v8.5)
在本课程中您将会学到:
- 7.4 版本后 Fleet 采集中间层服务器基本定型,正在发挥着巨大的作用
- Elastic Agent 正在逐步成为万金油式的边缘端管理工具
- 熟悉掌握 Elasticsearch & Kibana 最新的安全配置模型
- Fleet 服务器的部署,用策略集中式实现 Elastic Agent 采集日志和指标的工作
- 搭建本地采集代理程序安装包下载服务器,为简化测试环境
- 体验可观测性和安全管理方案的开箱即用功能
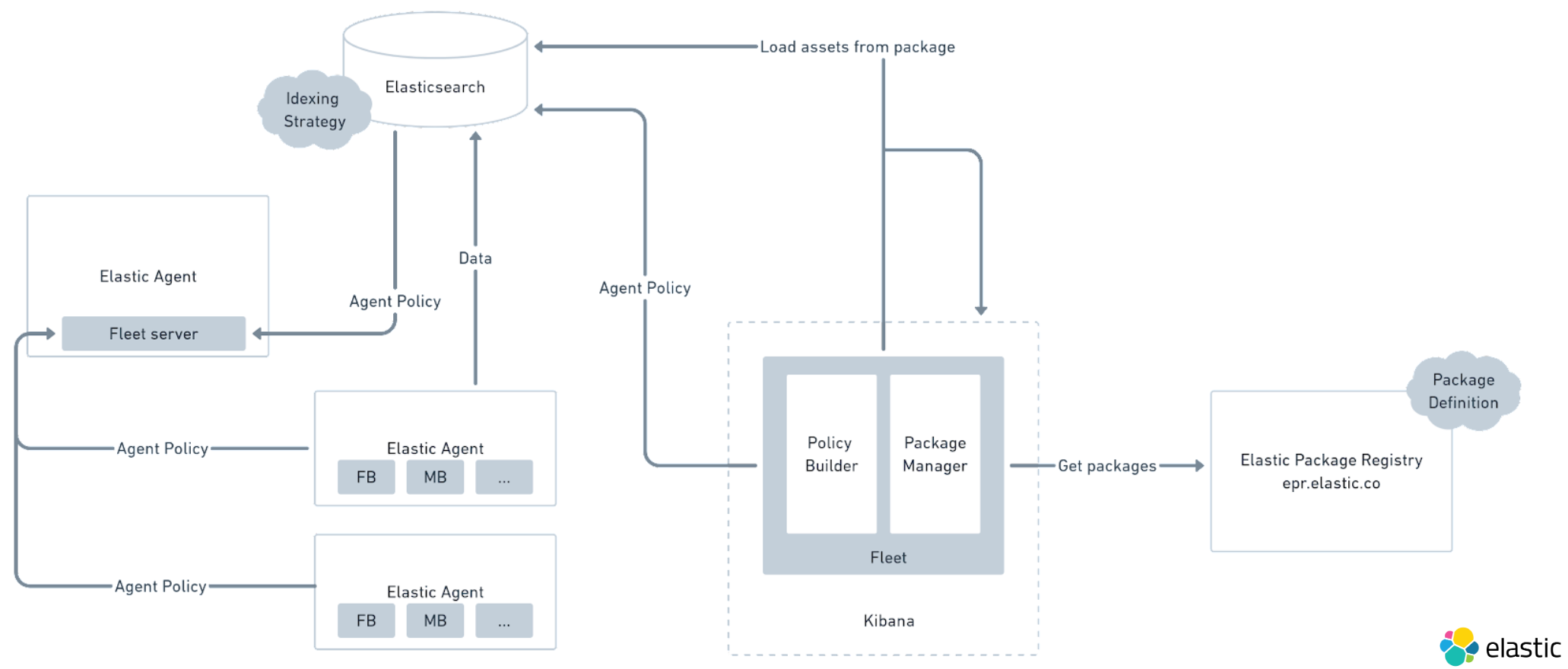
核心组件概述:
- Elastic Agent : 是一个万能安装配置工具,它既可以安装部署 Fleet server ,也在被管理节点上部署各种 Beats 采集端程序,这就意味着你再也不用手工的安装配置运行多个不同 Beats 程序了。
- Fleet server : 批量管理所有被管理节点(采集端服务器)的策略分发服务器,它负责注册节点接入新的被管理服务器,并持续更新维护所有后续的配置变更。
- Fleet app【 Kibana 端】 :Kibana 提供了对 Fleet 服务器,及以下所有被管理节点的控制平面。包括 Policy Builder 管理策略构建器和 Package Manager 包管理器两个部分。
- Elasticsearch :存储所有代理管理策略,采集代理程序和 Fleet 服务器所需要的安装包配置信息。
- Elastic Agent 【FB Filebeat ,MB Metricbeat 日志,指标等采集代理】:向 Fleet server 定期报到,并查看是否有代理策略更新;如果有新的 Beat 需要安装,从策略中指定的 ‘安装包下载服务器’ 下载并安装新的组件,将采集到的数据发送到 Elasticsearch 服务器。
- Elastic Package Registry : 所有可以被 Elastic Agent 管理的组件程序都需要特定的安装方式和可参数化配置,从 Elastic 官方网站下载,也可以用 Docker 方式在内网建立中继服务器。
本教程的示例测试环境:
- 虚拟机 A :Red Hat Enterprise Linux OS - 192.168.10.113 , 用于安装 Elasticsearch , Kibana ,Fleet 服务器, Beats 安装包下载服务器。
- 虚拟机 B Red Hat Enterprise Linux OS - 192.168.10.135 , 用于使用 Elastic Agent 部署各种 Beats 实现各种采集功能。
安装 Elasticsearch
在虚拟机 A 上完成本章节操作。
SSH 登录到操作系统,下载 Elasticsearch 的 rpm 安装包,用 rpm 的方式安装 Elasticssearch 服务器 dnf install -y elasticsearch-8.5.0-x86_64.rpm 。
[root@elk-01 ~]# dnf install elasticsearch-8.5.0-x86_64.rpm
Updating Subscription Management repositories.
Red Hat Enterprise Linux 9 for x86_64 - BaseOS (RPMs) 3.9 kB/s | 4.1 kB 00:01
Red Hat Enterprise Linux 9 for x86_64 - AppStream (RPMs) 3.9 kB/s | 4.1 kB 00:01
Dependencies resolved.
=============================================================================================================================
Package Architecture Version Repository Size
=============================================================================================================================
Installing:
elasticsearch x86_64 8.5.0-1 @commandline 540 M
Transaction Summary
=============================================================================================================================
Install 1 Package
Total size: 540 M
Installed size: 1.1 G
Is this ok [y/N]: y
Downloading Packages:
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Running scriptlet: elasticsearch-8.5.0-1.x86_64 1/1
Creating elasticsearch group... OK
Creating elasticsearch user... OK
Installing : elasticsearch-8.5.0-1.x86_64 1/1
Running scriptlet: elasticsearch-8.5.0-1.x86_64 1/1
--------------------------- Security autoconfiguration information ------------------------------
Authentication and authorization are enabled.
TLS for the transport and HTTP layers is enabled and configured.
The generated password for the elastic built-in superuser is : guJrLagKN5bsmUh72bha
If this node should join an existing cluster, you can reconfigure this with
'/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>'
after creating an enrollment token on your existing cluster.
You can complete the following actions at any time:
Reset the password of the elastic built-in superuser with
'/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'.
Generate an enrollment token for Kibana instances with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana'.
Generate an enrollment token for Elasticsearch nodes with
'/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node'.
-------------------------------------------------------------------------------------------------
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
/usr/lib/tmpfiles.d/elasticsearch.conf:1: Line references path below legacy directory /var/run/, updating /var/run/elasticsearch → /run/elasticsearch; please update the tmpfiles.d/ drop-in file accordingly.
Verifying : elasticsearch-8.5.0-1.x86_64 1/1
Installed products updated.
Installed:
elasticsearch-8.5.0-1.x86_64
Complete!
[root@elk-01 ~]#
安装完毕之后,查看 Elasticsearch 配置文件的默认参数:egrep -v "#|^$" /etc/elasticsearch/elasticsearch.yml;用 vi 编辑器打开 vi /etc/elasticsearch/elasticsearch.yml 配置文件 ; 在这个默认配置文件中寻找类似这样的一行 cluster.initial_master_nodes: ["elk-01"] ;将这一行注释掉。
然后在此配置文件的最下面增加下面这几行。
cluster.name: test-elk-015
discovery.type: single-node
network.host: 192.168.10.113
xpack.security.authc.api_key.enabled: true
启动 Elasticsearch 服务,并查看服务的状态。
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
systemctl status elasticsearch
在使用 ES 前,可以先修改ES服务初始化的内建用户密码,改成自己好记的安全可控密码。否则需要到 ES 的启动日志里寻找系统自动生产的管理员密码。
运行 /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic -i 命令修改 ES 的管理员账号 elastic 的密码。
[root@elk-01 ~]# /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic -i
This tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Re-enter password for [elastic]:
Password for the [elastic] user successfully reset.
在启动 ES 服务前,打开后续测试所需要的防火墙端口。
firewall-cmd --permanent --add-port=9200/tcp
firewall-cmd --permanent --add-port=5601/tcp
firewall-cmd --permanent --add-port=8220/tcp
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --reload
在浏览器里访问 es 的访问网址 https://192.168.10.133:9200/ ,忽略关于证书的安全提示,输入上面所修改的 elastic 账户信息,测试是否可以正常登录。
安装 Kibana
在虚拟机 A 上完成本章节操作。
下载 Kibana 的 rpm 安装包到服务器,然后执行 dnf install kibana-8.5.0-x86_64.rpm 安装命令
[root@elk-01 ~]# dnf install kibana-8.5.0-x86_64.rpm
Updating Subscription Management repositories.
Last metadata expiration check: 0:22:56 ago on Sun 16 Oct 2022 02:20:20 PM CST.
Dependencies resolved.
=======================================================================================================================================
Package Architecture Version Repository Size
=======================================================================================================================================
Installing:
kibana x86_64 8.5.0-1 @commandline 274 M
Transaction Summary
=======================================================================================================================================
Install 1 Package
Total size: 274 M
Installed size: 649 M
Is this ok [y/N]: y
Downloading Packages:
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Running scriptlet: kibana-8.5.0-1.x86_64 1/1
Installing : kibana-8.5.0-1.x86_64 1/1
Running scriptlet: kibana-8.5.0-1.x86_64 1/1
Creating kibana group... OK
Creating kibana user... OK
Created Kibana keystore in /etc/kibana/kibana.keystore
/usr/lib/tmpfiles.d/elasticsearch.conf:1: Line references path below legacy directory /var/run/, updating /var/run/elasticsearch → /run/elasticsearch; please update the tmpfiles.d/ drop-in file accordingly.
Verifying : kibana-8.5.0-1.x86_64 1/1
Installed products updated.
Installed:
kibana-8.5.0-1.x86_64
Complete!
在启动 Kiban 服务器之前,先需要创建 Kibana 需要的各种加密 key ,执行这个 /usr/share/kibana/bin/kibana-encryption-keys generate 命令。
/usr/share/kibana/bin/kibana-encryption-keys generate
xpack.encryptedSavedObjects.encryptionKey: 2e71f1b16031c2b111b76276268dbf9e
xpack.reporting.encryptionKey: 84cb58b5e944fa9f65f73382384612a5
xpack.security.encryptionKey: c5ac5b306ee011838a67e2eaf4154dd0
记录以上三行配置参数,并增加2行新参数,将它们全部添加到 Kibana 默认的配置文件中。
server.host: 192.168.10.113
server.publicBaseUrl: "http://192.168.10.113:5601"
xpack.encryptedSavedObjects.encryptionKey: 2e71f1b16031c2b111b76276268dbf9e
xpack.reporting.encryptionKey: 84cb58b5e944fa9f65f73382384612a5
xpack.security.encryptionKey: c5ac5b306ee011838a67e2eaf4154dd0
用 vi 打开 Kibana 的默认配置文件 /etc/kibana/kibana.yml ,将上面的 5 行配置参数添加到文件中。
在命令行执行 systemctl enable --now kibana 命令启动 Kibana 服务器.
然后执行命令 tail -f /var/log/messages , 在日志中寻找 Kibana 服务启动的信息,等待出现 Kibana 配置的访问 URL。在日志中寻找类似这样的信息:
Oct 18 10:36:48 elk-01 kibana[2163]: i Kibana has not been configured.
Oct 18 10:36:48 elk-01 kibana[2163]: Go to http://192.168.10.113:5601/?code=732948 to get started.
然后在浏览器中打开这个类似这个 http://192.168.1.113:5601/?code=732948 网址。网页中会出现一个大输入框,等待输入Kibana 注册秘钥。
在命令行执行 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana 命令,从而获取 Kibana 的注册令牌。
[root@elk-01 ~]# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
eyJ2ZXIiOiI4LjQuMyIsImFkciI6WyIxOTIuMTY4LjEwLjEwOjkyMDAiXSwiZmdyIjoiZTdlOTdlZWU2YWVlYjVmYTczZWM1YTVkNzBiNDJkZGUzZjlkZmNjMDJhNTVmZDcwZjAxOTQwZmExNzE5YWM2MSIsImtleSI6IjNHLVEzNE1CYnA4c3p4TEZEZXpCOk0wUDMzRC1VVFAyT0ZxQVFBekNKSWcifQ==
将这个 Token 复制到网页里,完成Kibana 的初始化配置,最后用 es 的管理员账号登录 Kibana。
安装完成 Kibana 之后,启用试用版许可证,启用集群自监控功能。
安装 Fleet 服务器
在虚拟机 A 上完成本章节操作。
在 Kibana 的菜单中找到, Fleet 选项,点击 Settings,然后点击 Edit Hosts ,选择增加 Fleet server 配置信息,输入 https://192.168.1.113:8220 ,注意这里必须是 https协议。
回到 Fleet 主页,找到 agent 管理的地方,按照流程做,点击创建 Fleet Server 配置。然后就会在页面上生成 Fleet 服务器的安装配置命令。
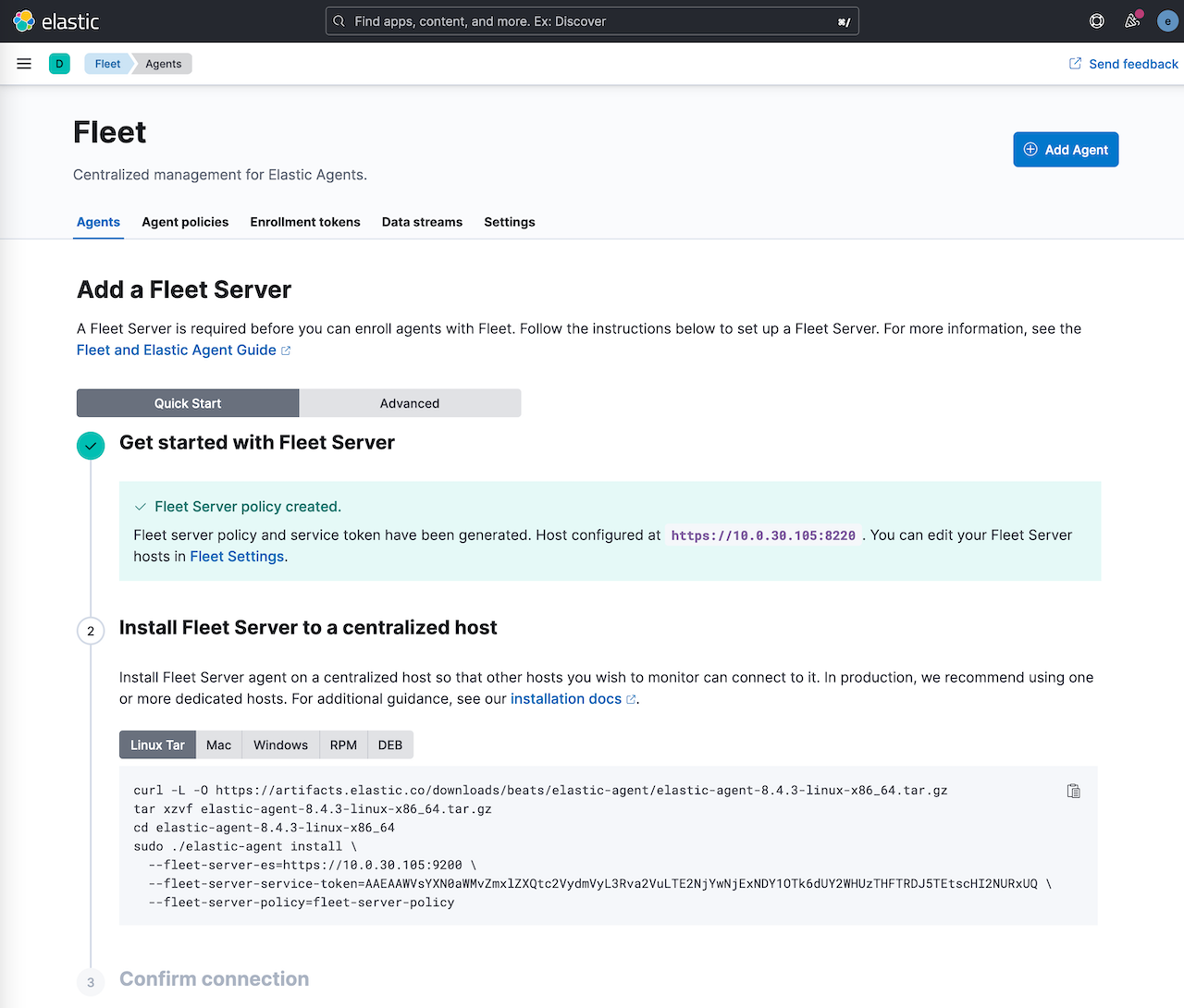
按着提示的命令参数安装 Fleet 服务器。
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.5.0-linux-x86_64.tar.gz
cd elastic-agent-8.5.0-linux-x86_64
sudo ./elastic-agent install \
--fleet-server-es=https://192.168.10.113:9200 \
--fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE2Njc3Mjk3Mzc3MTQ6ZWRFNGtlWGJTSWU1TktJTXRtR0U5QQ \
--fleet-server-policy=fleet-server-policy \
--fleet-server-es-ca-trusted-fingerprint=772b777ed4dd557965cb3e1735f7b15b8cd6312372e8ba4d967f55d8beecd702
在 Fleet 服务器正常启动以后,上面创建 Fleet 服务器配置的网页上的最后一步就会显示:Fleet 服务器已经连接正常,等待注册 Elastic Agent 。这样表明 Fleet 服务器已经安装正常,并且运行在默认的代理配置采集策略下。
可以在 Kibana 的界面里查看 Fleet 服务器的监控信息。点击 Kibana 左上角的菜单:Observability -> Infrastructure -> Inventory ,即可看到 Fleet 服务器的监控数据。
搭建本地安装包下载服务器
为了让局域网中的被管理操作系统能在本地局域网里下载到 Elastic Stack 技术栈中,所有可以通过 Fleet 服务器管理(安装、配置、升级、删除等)的组件,我们可以参考文档的方法:https://www.elastic.co/guide/en/fleet/8.5/air-gapped.html#host-artifact-registry在本地部署一个安装包下载服务器。
首先,安装一个 Nginx 服务器,在根目录下创建目录 downloads ,并且运行下面的下载脚本。
curl -O https://artifacts.elastic.co/downloads/apm-server/apm-server-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/apm-server/apm-server-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/apm-server/apm-server-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/auditbeat/auditbeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/auditbeat/auditbeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/auditbeat/auditbeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/heartbeat/heartbeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/osquerybeat/osquerybeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/osquerybeat/osquerybeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/osquerybeat/osquerybeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/beats/packetbeat/packetbeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/beats/packetbeat/packetbeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/beats/packetbeat/packetbeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/cloudbeat/cloudbeat-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/cloudbeat/cloudbeat-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/cloudbeat/cloudbeat-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/endpoint-dev/endpoint-security-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/endpoint-dev/endpoint-security-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/endpoint-dev/endpoint-security-8.5.0-linux-x86_64.tar.gz.asc
curl -O https://artifacts.elastic.co/downloads/fleet-server/fleet-server-8.5.0-linux-x86_64.tar.gz
curl -O https://artifacts.elastic.co/downloads/fleet-server/fleet-server-8.5.0-linux-x86_64.tar.gz.sha512
curl -O https://artifacts.elastic.co/downloads/fleet-server/fleet-server-8.5.0-linux-x86_64.tar.gz.asc
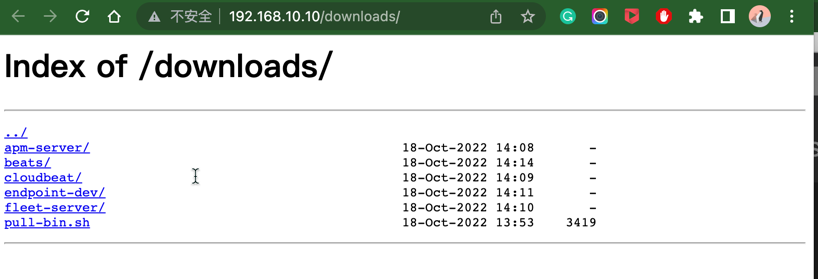
将下载后的目录结构整理的和下载路径一致,建立所有必要的子目录,整理之后的目录结构如下所示:
[root@elk-01 html]# tree downloads/
downloads/
├── apm-server
│ ├── apm-server-8.5.0-linux-x86_64.tar.gz
│ ├── apm-server-8.5.0-linux-x86_64.tar.gz.asc
│ └── apm-server-8.5.0-linux-x86_64.tar.gz.sha512
├── beats
│ ├── auditbeat
│ │ ├── auditbeat-8.5.0-linux-x86_64.tar.gz
│ │ ├── auditbeat-8.5.0-linux-x86_64.tar.gz.asc
│ │ └── auditbeat-8.5.0-linux-x86_64.tar.gz.sha512
│ ├── elastic-agent
│ │ ├── elastic-agent-8.5.0-linux-x86_64.tar.gz
│ │ ├── elastic-agent-8.5.0-linux-x86_64.tar.gz.asc
│ │ └── elastic-agent-8.5.0-linux-x86_64.tar.gz.sha512
│ ├── filebeat
│ │ ├── filebeat-8.5.0-linux-x86_64.tar.gz
│ │ ├── filebeat-8.5.0-linux-x86_64.tar.gz.asc
│ │ └── filebeat-8.5.0-linux-x86_64.tar.gz.sha512
│ ├── heartbeat
│ │ ├── heartbeat-8.5.0-linux-x86_64.tar.gz
│ │ ├── heartbeat-8.5.0-linux-x86_64.tar.gz.asc
│ │ └── heartbeat-8.5.0-linux-x86_64.tar.gz.sha512
│ ├── metricbeat
│ │ ├── metricbeat-8.5.0-linux-x86_64.tar.gz
│ │ ├── metricbeat-8.5.0-linux-x86_64.tar.gz.asc
│ │ └── metricbeat-8.5.0-linux-x86_64.tar.gz.sha512
│ ├── osquerybeat
│ │ ├── osquerybeat-8.5.0-linux-x86_64.tar.gz
│ │ ├── osquerybeat-8.5.0-linux-x86_64.tar.gz.asc
│ │ └── osquerybeat-8.5.0-linux-x86_64.tar.gz.sha512
│ └── packetbeat
│ ├── packetbeat-8.5.0-linux-x86_64.tar.gz
│ ├── packetbeat-8.5.0-linux-x86_64.tar.gz.asc
│ └── packetbeat-8.5.0-linux-x86_64.tar.gz.sha512
├── cloudbeat
│ ├── cloudbeat-8.5.0-linux-x86_64.tar.gz
│ ├── cloudbeat-8.5.0-linux-x86_64.tar.gz.asc
│ └── cloudbeat-8.5.0-linux-x86_64.tar.gz.sha512
├── endpoint-dev
│ ├── endpoint-security-8.5.0-linux-x86_64.tar.gz
│ ├── endpoint-security-8.5.0-linux-x86_64.tar.gz.asc
│ └── endpoint-security-8.5.0-linux-x86_64.tar.gz.sha512
├── fleet-server
│ ├── fleet-server-8.5.0-linux-x86_64.tar.gz
│ ├── fleet-server-8.5.0-linux-x86_64.tar.gz.asc
│ └── fleet-server-8.5.0-linux-x86_64.tar.gz.sha512
└── pull-bin.sh
12 directories, 34 files
[root@elk-01 html]#
注意:以上不包含 windows 和 macos 平台的软件包,如果有必要,还需要自行填补完整。
为了方便查看这个目录的内容,修改 nginx 的默认配置文件,在 http 这个部分增加下面三个参数:
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
重启 Nginix 服务器后,在浏览器中可以访问: http://192.168.10.113/downloads/ ,确保可以看到正确的目录结构和文件。
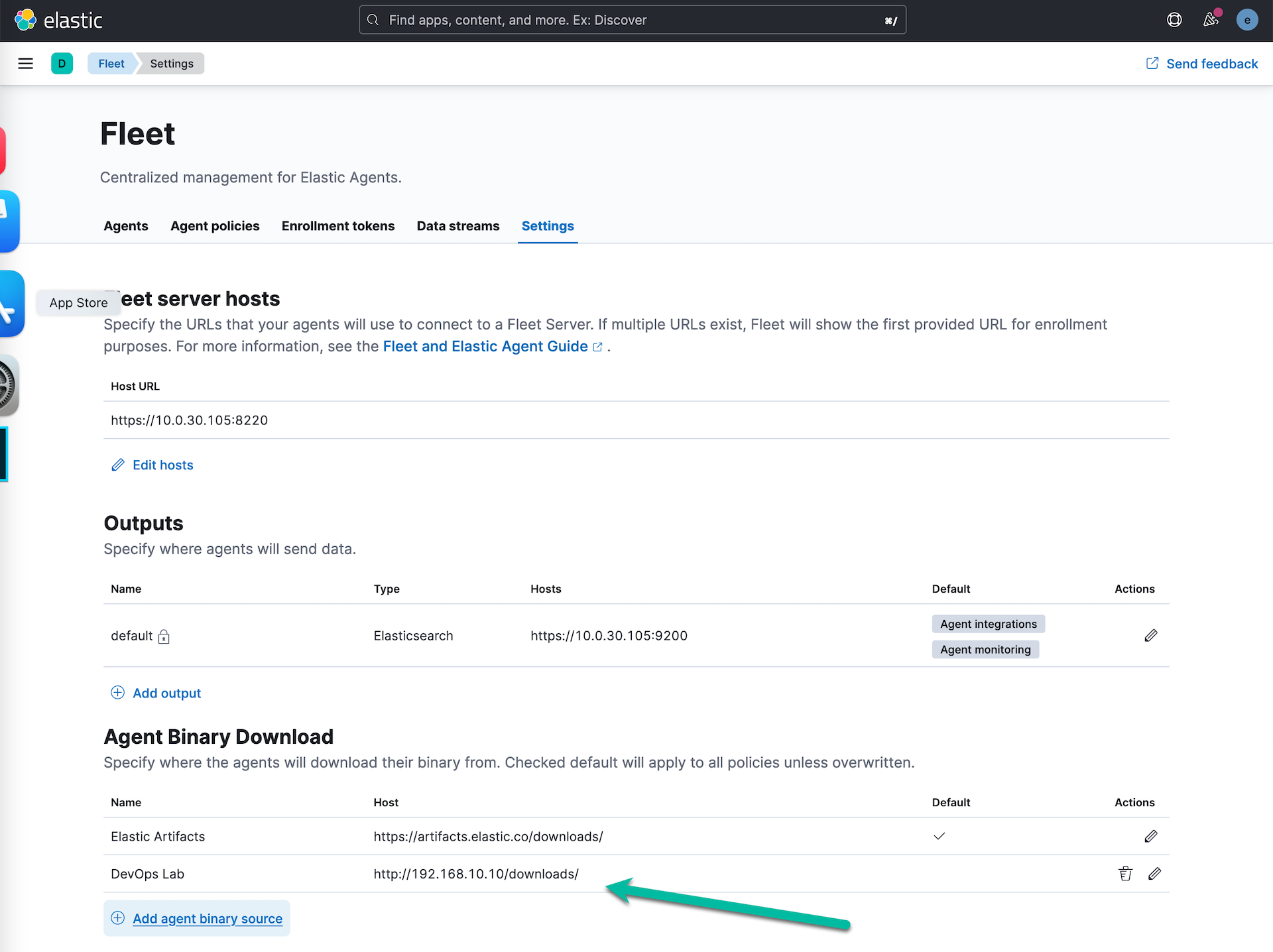
进入 Fleet 的配置页面,在 Agent Binary Download 下面点击 “Add agent binary source” ,新建一个新的代理安装包下载来源网站。
在 Agent Policies 页面新建一个新的测试用 Agent 管理策略,名为 “my-policy2”;进入这个策略的配置界面,修改 Agent Binary Download 为刚才创建的下载源。保存并测试这个策略。
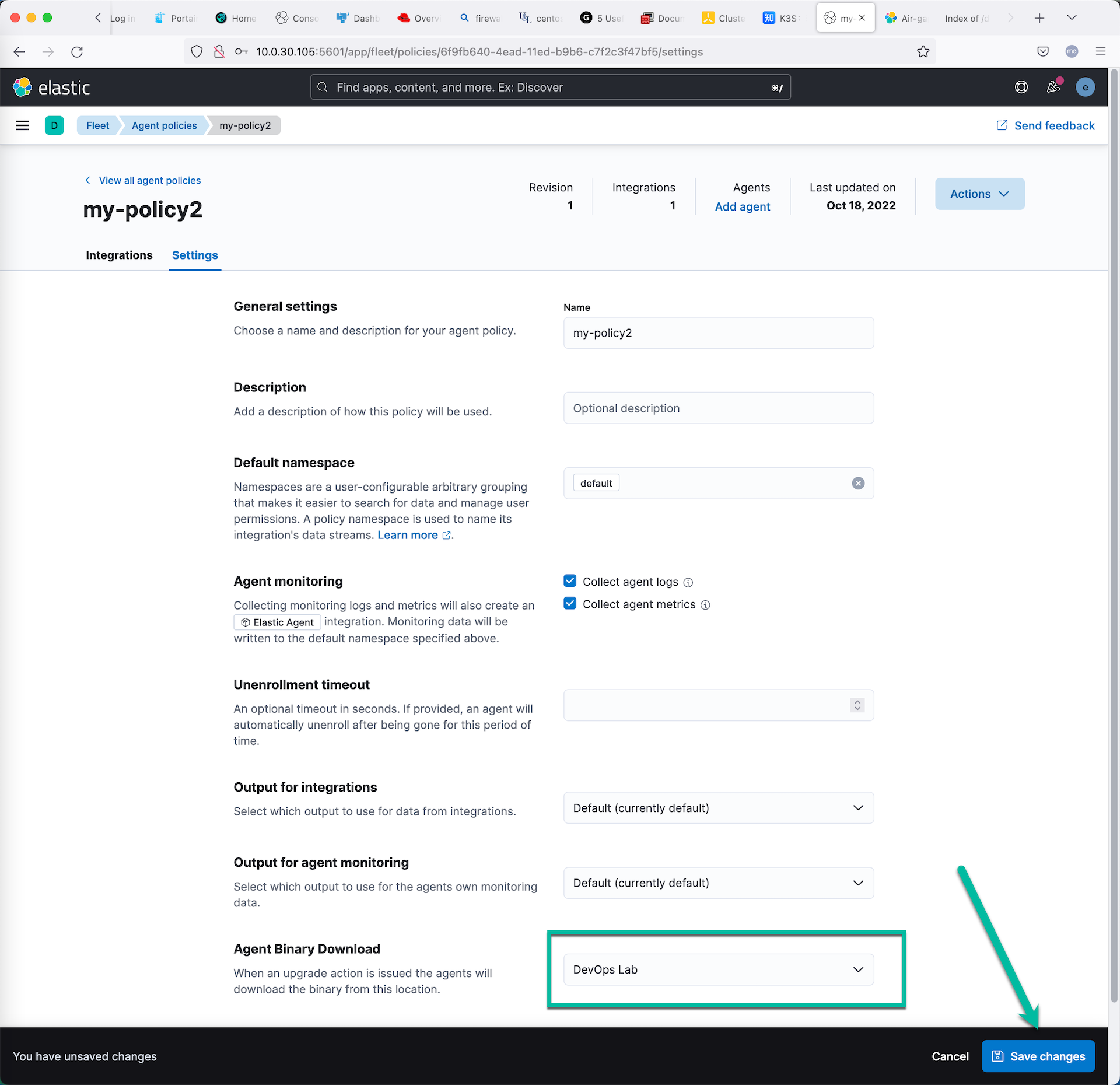
点击 “Add agent” 连接,获取下面的新注册代理注册命令。
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz tar xzvf elastic-agent-8.5.0-linux-x86_64.tar.gz cd elastic-agent-8.5.0-linux-x86_64 sudo ./elastic-agent install --url=https://192.168.1.113:8220 --enrollment-token=R29qRDZZTUJtUENhc0ZFTFNDSW06bVFOeW5vcUpTQmFmZDBwLUgyTDBYZw==
修改这些命令参数,将 tar.gz 的下载地址改为本地搭建的下载服务器地址,如下:
curl -L -O http://192.168.10.10/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.5.0-linux-x86_64.tar.gz
cd elastic-agent-8.5.0-linux-x86_64
sudo ./elastic-agent install --url=https://192.168.1.113:8220 --enrollment-token=R29qRDZZTUJtUENhc0ZFTFNDSW06bVFOeW5vcUpTQmFmZDBwLUgyTDBYZw== --insecure
用新创建的 Agent 管理策略,一键式安装 Elastic Agent 并注册到 Fleet 服务器。由于这个策略使用了本地的安装包(默认会使用到 Filebeat 和 Metricbeat),所以它的部署速度应该会比较快。
Elastic Agent 的常用命令:
- 用这个命令
elastic-agent status也可以确认当前的运行状态和模块。 - 用这个命令
elastic-agent inspect也可以确认Fleet 服务器下发过来的配置。
安装 Elastic Agent 监控代理
在虚拟机 B 上完成本章节操作。
在 Fleet 的管理界面中新增一个名为 my-policy1 的管理策略,避免和 Fleet 服务器使用相同的策略。点击 Add agent 连接,获取如下代理注册命令。
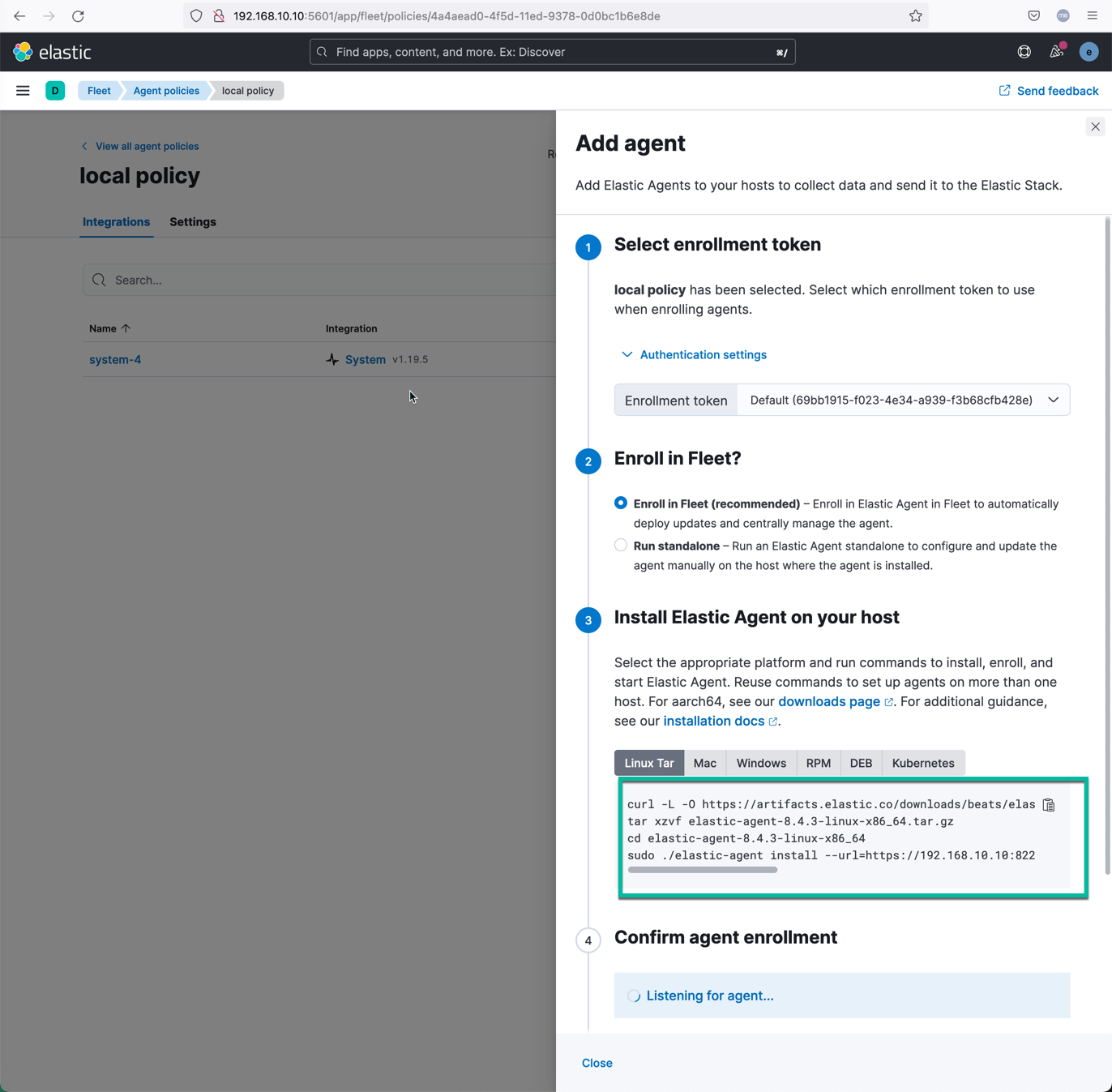
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.5.0-linux-x86_64.tar.gz
cd elastic-agent-8.5.0-linux-x86_64
sudo ./elastic-agent install --url=https://192.168.1.113:8220 --enrollment-token=NW9ZTjZZTUJtUENhc0ZFTDI5SV86MkZQT1hlc2dUOEdWZnRrWWhNbXVjdw==
将上面的命令复制到一个写字板中,修改其中的两条命令:
- 修改下载网址为前文所搭建的本地下载网址
- 修改最后一条命令,在最后增加
--insecure参数,如果不加这个参数,远程 Agent 的注册就会由于验证 es 服务器端证书而失败。
curl -L -O http://192.168.10.113/downloads/beats/elastic-agent/elastic-agent-8.5.0-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.5.0-linux-x86_64.tar.gz
cd elastic-agent-8.5.0-linux-x86_64
sudo ./elastic-agent install --url=https://192.168.10.113:8220 --enrollment-token=RHVudFRJUUIzZTZQd0tCdlhBTFY6NldXMFlVellUYmFrdVc4UGRHUDVSdw== --insecure
通过执行上面的命令,我们就在被管理服务器上,一键式的安装了用于数据采集功能的 Elastic Agent ,并将其注册到 Fleet 服务器上。
Elatic Agent 正常运行几分钟有,既可以在 Kibana 中的 Observability 的界面和 Dashbard 中看到这个被管理服务器的监控数据。
Elastic Agent 的安装方式:
- tar.gz : 在所有操作系统上「Windows,Linux,MacOS」都推荐,由于这里下载的 tar.gz 的安装包,用命令行一键式的安装成功以后,在操作系统中就会创建出后台的 Elastic Agent 主服务,这个服务进程会自动化其他所有 Beats 程序的安装工作,根据 Agent 策略,如果需要安装新的 Beats 就会下载安装,如果有新的版本就会根据策略升级,这样就解决了后续 Agent 这一侧的配置的生命周期管理。
- PRM、DEB : 这种方式也支持,但是 Elastic Agent 软件/服务本身的版本升级无法自动化实现。
万用采集端的好处,新增 Packetbeat 采集模块
在虚拟机 A&B 上完成本章节操作。
为了验证这个功能,可以尝试更新当前的一个 policy,在其中增加 Packetbeat 数据采集能力。操作步骤如下:
- 打开当前的一个正在使用中 policy
- 点击 Add intergation 按钮,在众多选项中选择 Network Packet Capture 模块。
- 增加新的采集模块后,保存这个策略。
- 它更新了版本,观察 Fleet 界面上所有使用这个策略的节点的状态变化。
- 这些节点会自动的,很快的更新到新的管理策略中,Elastic Agent 会自动化安装 Packetbeat 采集模块。
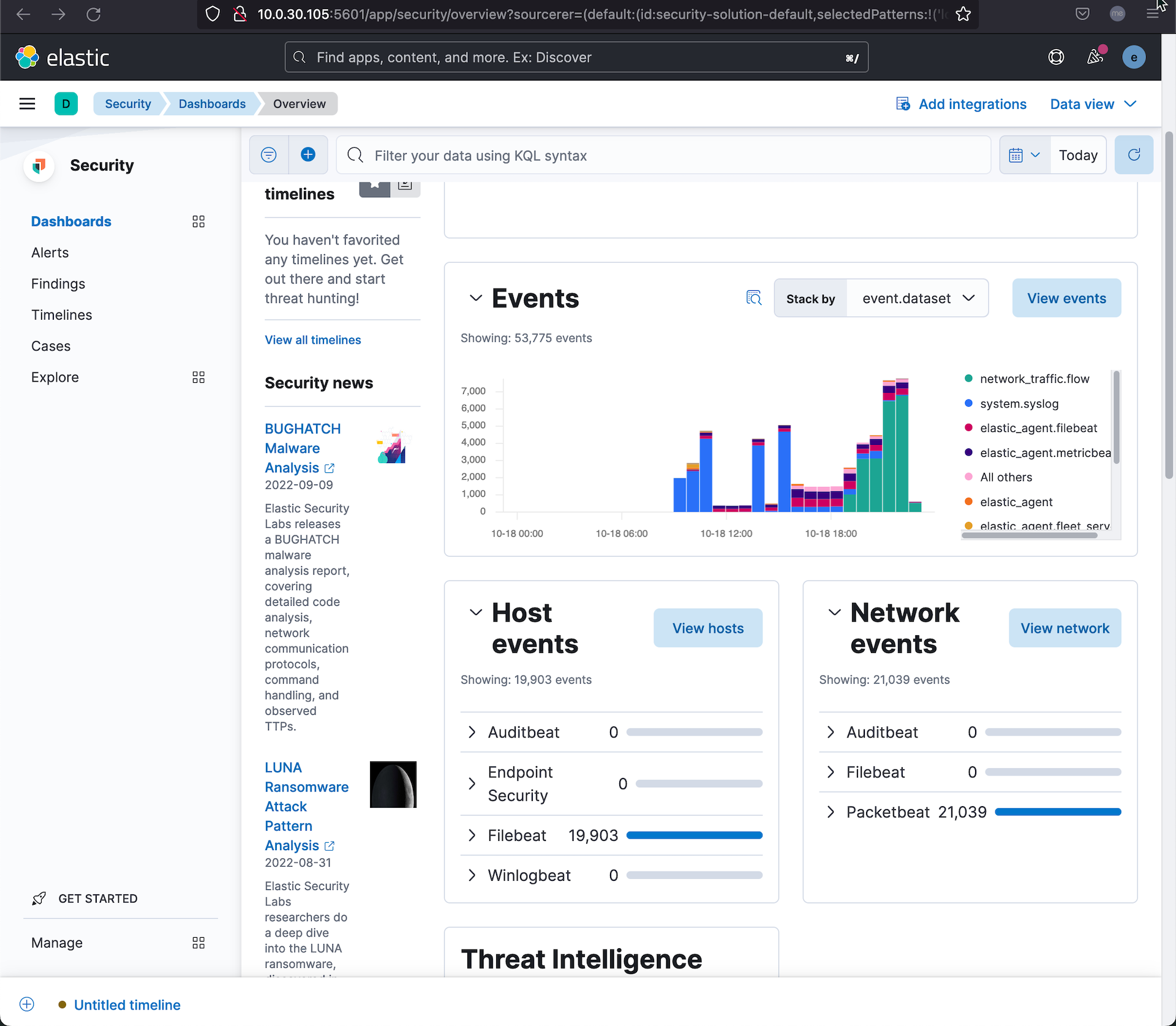
- 返回 Kiban ,进入安全管理解决方案,我们可以看到 Filebeat 和 Packetbeat 的采集结果。
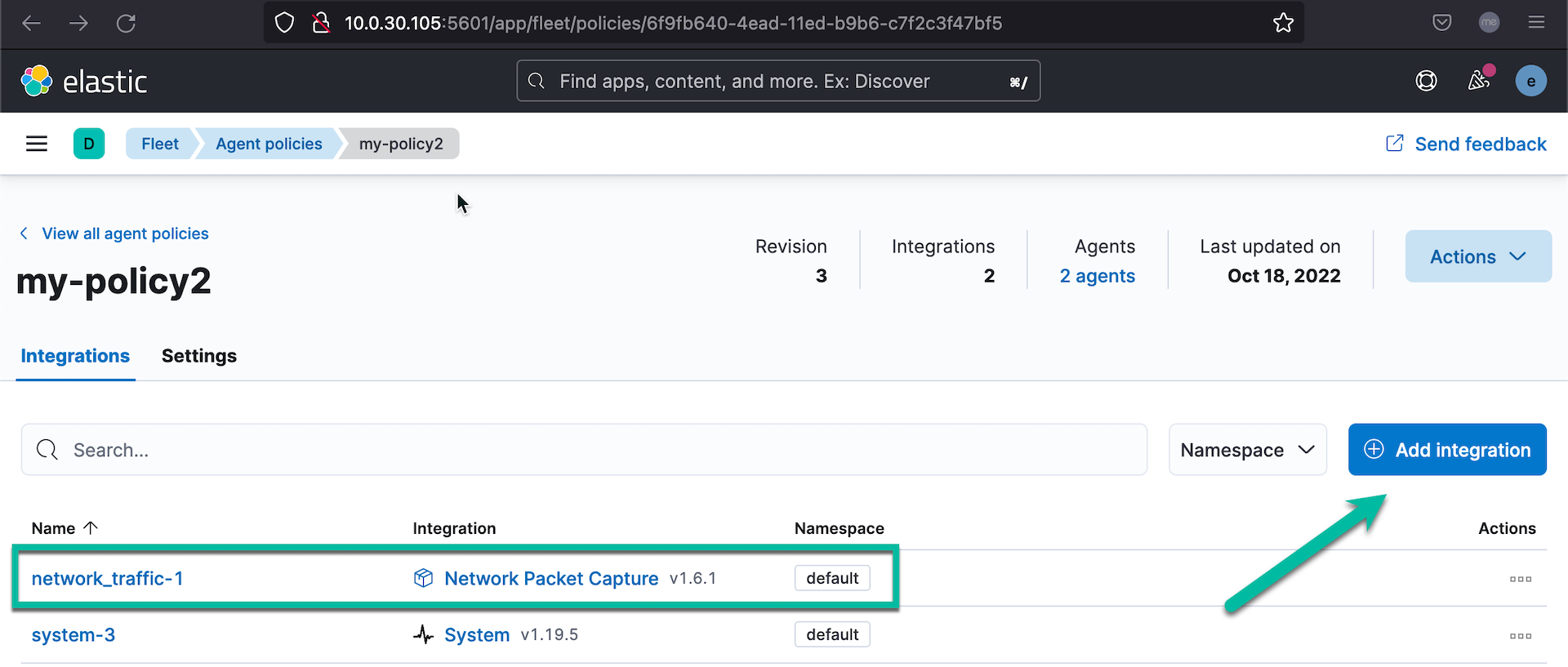
在策略更新了以后,我们没有在 Elastic Agent 端做任何操作,它就已经自动化的下载新的策略,并更新了自身。
常见问题
Elastic Agent 在采集数据的服务上安装正常,在 Fleet 服务器的管理界面中也可以看到其状态正常。但是在可观测性的页面中看不到它的任何数据。 主要是由于 Elasticsearch 服务器强制是用 https 协议,客户端没有配置好数字证书的话,必须在Fleet服务器的配置中规避掉,ssl 证书校验的功能。
其他可能的原因:Elastic Agent 采集端程序和 ES 后台服务器的通讯不正常,检查 9200 端口,用 curl + ES 服务器端的数字证书,用户名和密码,尝试访问 ES 的服务地址 https://192.168.10.10:9200。
也可以尝试在 Fleet 的管理页面上删除这个 Agent;然后在被管理服务器上,用命令 elastic-agent uninstall 删除服务,然后重新安装注册这个被管理服务器,注意在注册命令的最后面可以尝试增加这两个参数: --insecure --fleet-server-es-insecure 第一个参数是忽略 Fleet 服务器的 ssl 证书校验,第二个参数是忽略 es 服务器的 ssl 证书校验。或者尝试重新手工安装一遍 es 服务器上的 ca 根证书。