洞察 GitHub 开源项目的开发效能
开源项目的火热程度取决于技术创新和行业发展趋势,有很多风口浪尖的开源项目确实非常吸引人。GitHub 中的开源项目质量好不好,是不是数项目获得的星星就够了?该如何洞察开源项目的社区参与程度?如何判断项目核心开发团队的研发效能?为了回答这些颇具深度的问题,我们还需要对项目进行更深度的分析。本教程教你使用 Elastic Stack 构建 GitHub 开源项目的关键指标的分析看板,在 Kibana 中详细分析项目的几个重要维度。
学习目标
准备工作
首先需要在你的电脑上,进行下面的两项准备工作。你可以使用 Windows、macOS 或者 Linux 操作系统完成本教程的所有操作。
- 在浏览器中打开网址 https://www.elastic.co/downloads/past-releases#elasticsearch ; 下载 elasticsearch-7.17.0-darwin-aarch64.tar.gz 、kibana-7.17.0-darwin-aarch64.tar.gz 、 filebeat-7.17.0-darwin-x86_64.tar.gz 软件包。请自行选择正确的平台,以上 darwin-aarch64 软件包适用于 moacOS M1 平台;而 darwin-x86_64 软件包适用于 macOS Intel 平台。根据你使用的操作系统,下载正确的软件包。
- 在 GitHub 中创建 personal token,用于提升访问 GitHub Api 请求数限制。
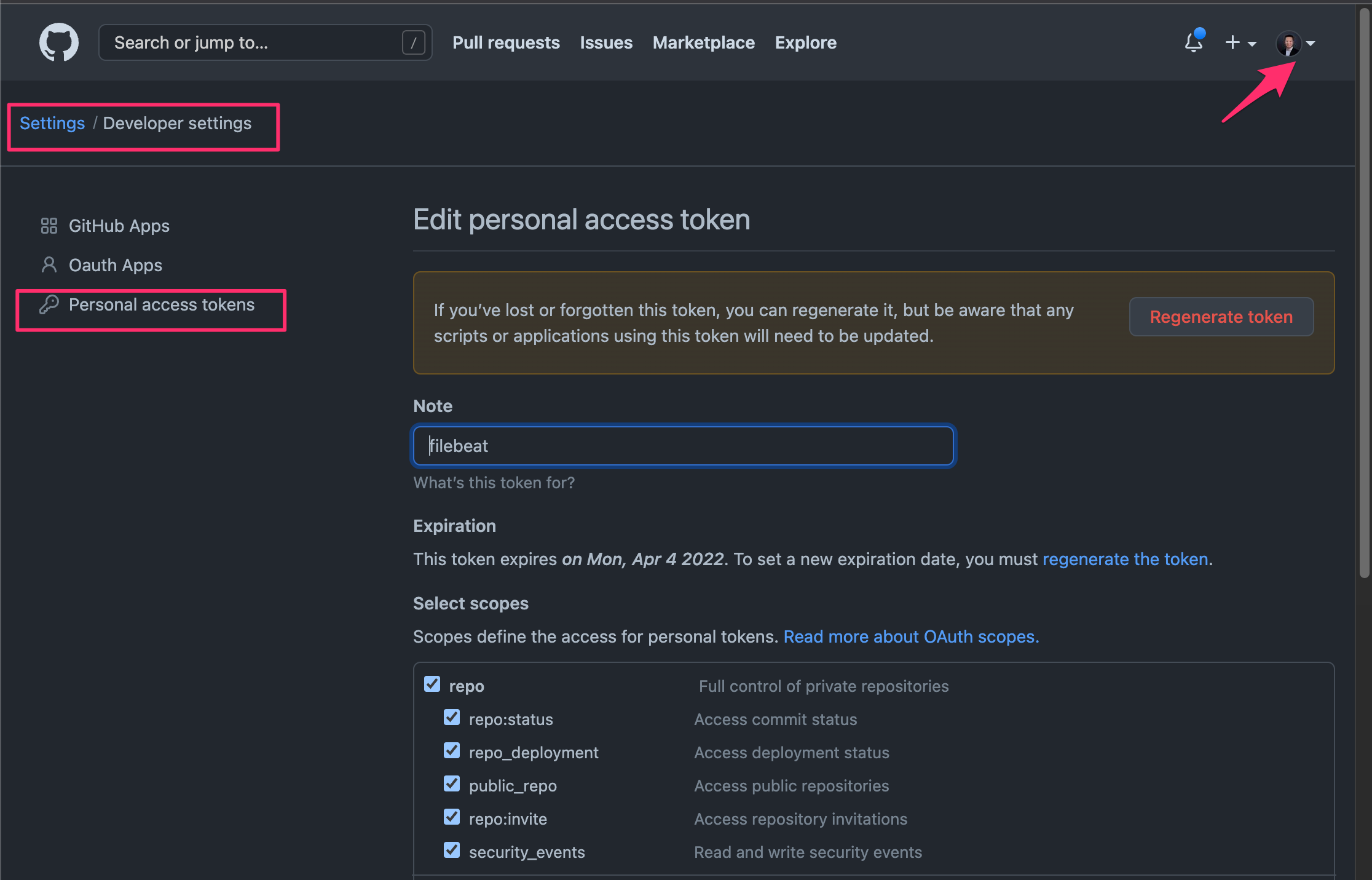
保存这个界面中的类似于这样的个人访问令牌 ghp_Tx9xAbV7O6fuXYZ1234567890 备用。
启动开发环境
- 启动 Elasticsearch 服务器:下面是在 macOS M1 平台上解压缩 Elasticsearch 软件包,进入解压后的软件包的目录,使用其可执行文件启动服务。
tar zxvf elasticsearch-7.17.0-darwin-aarch64.tar.gz
cd elasticsearch-7.17.0/bin
./elasticsearch -Enode.name=mac-m1
以上使用的命令是直接运行 Elasticsearch 可执行文件, ./elasticsearch -Enode.name=mac-m1 , 其中参数 -Enode.name=mac-m1 设定了当前节点的名称,你也可以使用你的主机名。
如果是在 Windows 平台上,使用解压缩软件将 zip 软件包解压后,打开 Windows 操作系统的命令行工具,进入解压后的目录中,执行 ./elasticsearch.exe -Enode.name=mac-m1 即可,对于下面的 Kibana 和 Filebeat 也是如法炮制。
- 启动 Kibana 服务器:
使用下面的命令启动 Kibana 服务器。
tar zxvf kibana-7.17.0-darwin-aarch64.tar.gz
cd kibana-7.17.0-darwin-aarch64/bin
./kibana
这样就启动了 Kibana 服务器,如果你使用的是远程的虚拟机或者云主机,需要在启动命令中加入一个参数即可,./kibana server -H 0.0.0.0, 这样 Kibana 就可以从远程的任意 Ip 地址访问。Kibana 默认会连接上一步所启动的 Elasticsearch 服务器,在这个开发环境中,默认没有启用用户名和密码认证,由于是临时的测试,生产环境中建议启用 Elasticsearch 的用户密码认证。
- 准备 Filebeat 的运行环境:解压缩 Filebeat 软件包,进入解压后的目录,备份默认的
filebeat.yml重命名为filebeat.yml.bk。
用下面的命令准备好 Filebeat 的运行环境。
tar zxvf filebeat-7.17.0-darwin-x86_64.tar.gz
cd filebeat-7.17.0-darwin-x86_64
mv filebeat.yml filebeat.yml.bk
- 初始化 Kibana 的配置。在浏览器中输入
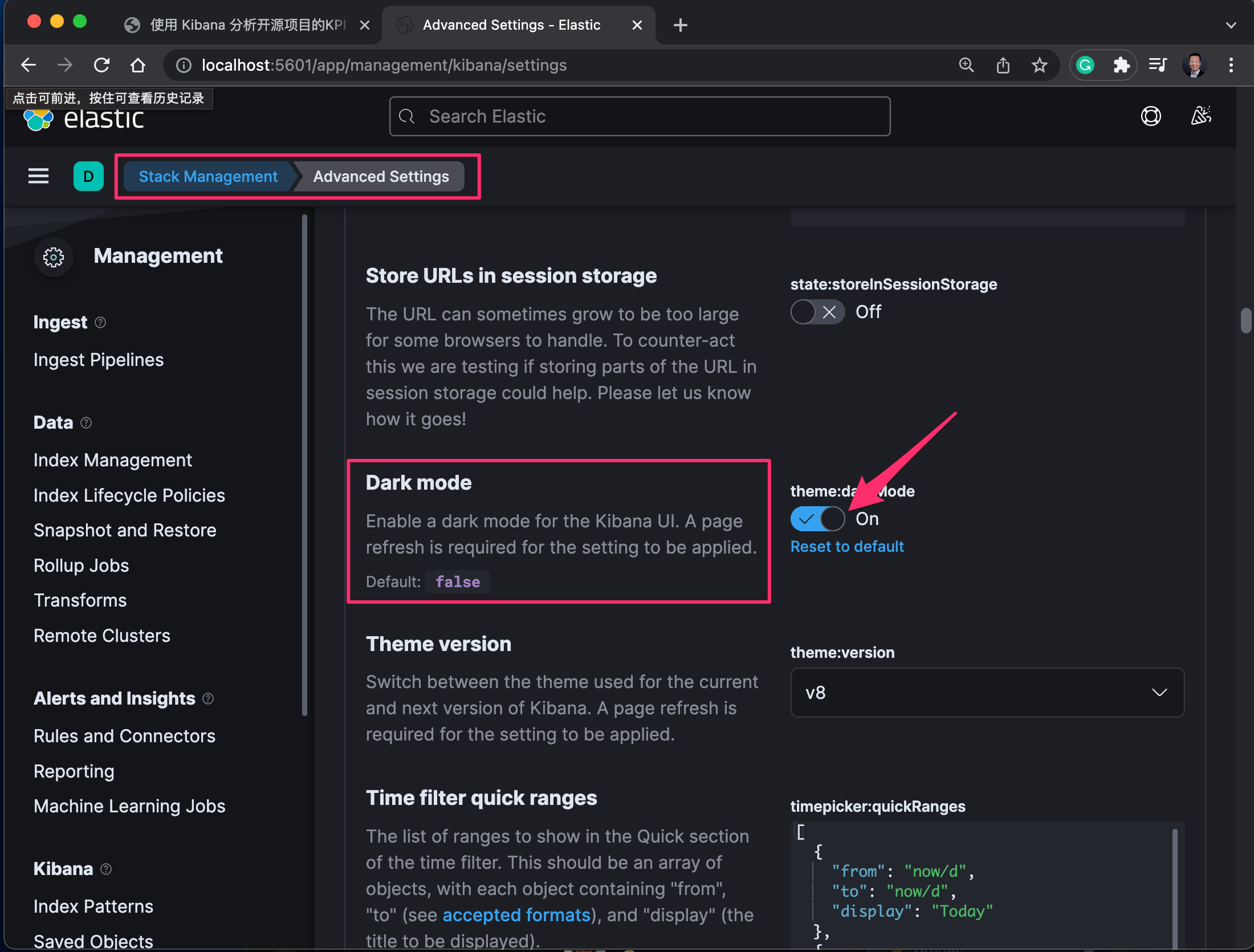
http://localhost:5601,在登陆了 Kibana 之后,点击左上角的图标,打开左侧隐藏菜单,找到 Stack Management –> Kibana –> Advanced Setting 页面中的这两个选项。
- 打开 “Dark mode” 选项,打开暗黑模式界面。
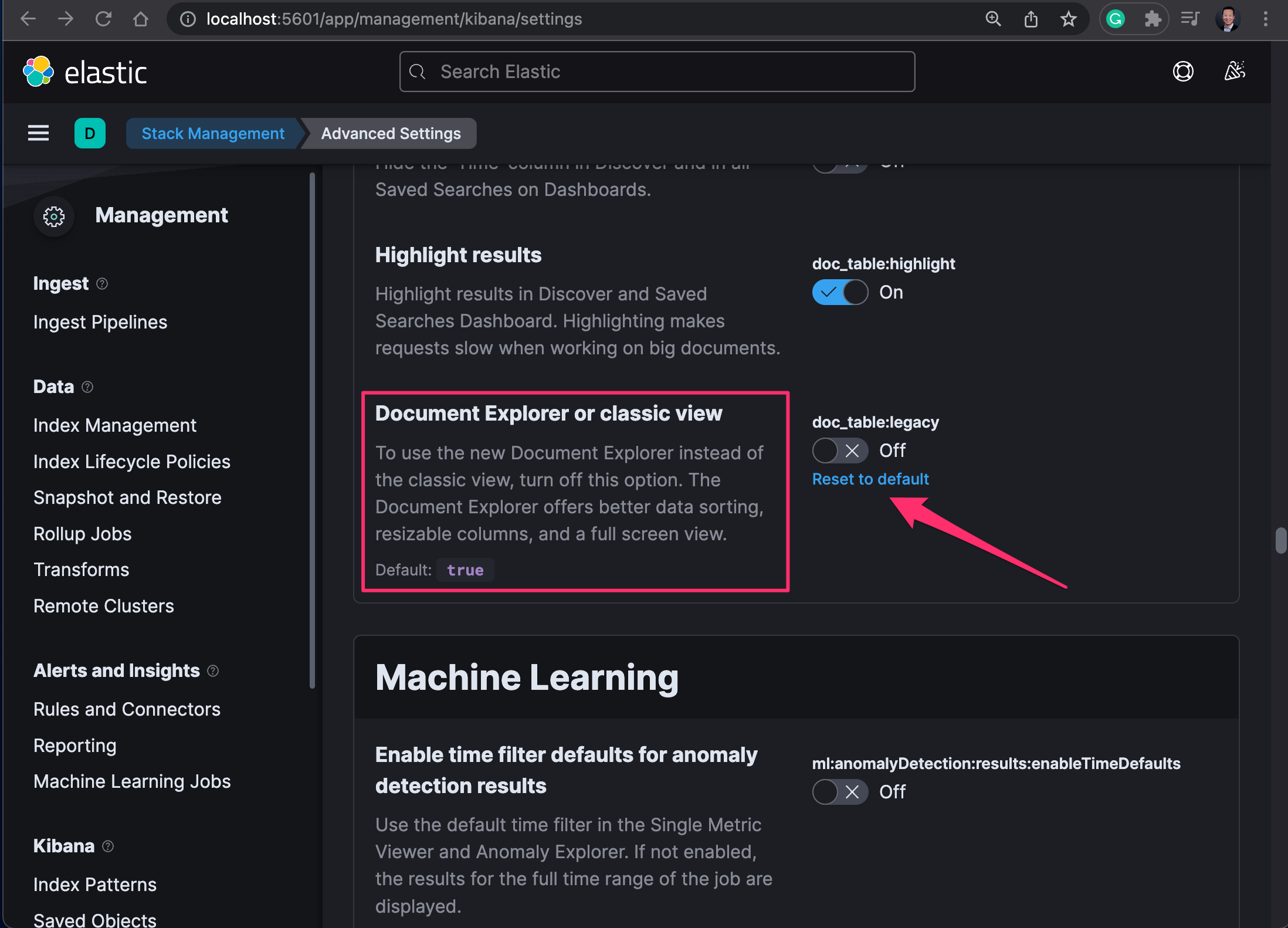
- 设置 “Document Explorer or classic view” 选项。关闭默认的 classic 经典视图模式。
自查点
下载示例配置文件
为了降低学习Kibana数据看板的搭建门槛,请下载准备好的示例文件。点击下面的下载按钮,或者访问网址:https://github.com/martinliu/sdp-dashboard/archive/refs/heads/main.zip
下载解压下载后的 zip 文件,其中的三个文件会被使用到:
- filebeat.yml : 完整的 Filebeat 配置参数模版。用它替换 Filebeat 的默认配置文件。本示例配置文件分析的是 Ansible 的 awx 项目 (Ansbile Tower 的开源版本),你也可以根据需要其替换为其它需要探索的项目。
- add_gh_fields.json : GitHub 项目属性扩展字段定义。将其放入 Filebeat 程序文件夹的目录中。
- export-v1.0.ndjson : Kibana 可视化数据分析看板模版。后续将其导入到新安装的 Kibana 中。
以上三个文件适用于任何操作系统。如果你的操作系统中安装了 Git 客户端,你可以直接 clone 这些示例文件所在项目到本地
git clone https://github.com/martinliu/sdp-dashboard.git。
使用 Filebeat 下载项目数据
Filebeat 包含多种数据摄入模块:
- AWS CloudWatch
- AWS S3
- Azure Event Hub
- Cloud Foundry
- Container
- filestream
- GCP Pub/Sub
- HTTP Endpoint
- HTTP JSON
- journald
- Kafka
- Log
- MQTT
- NetFlow
- Office 365 Management Activity API
- Redis
- Stdin
- Syslog
- TCP
- UDP
以上各种模块已经覆盖很多类型的数据源,灵活使用这些模块,就可以将 Filebeat 当作一个 mini 版的 Logstash 使用,当然 Logstash 包含了更丰富的摄入模块和数据处理能力。本教程聚焦在 “HTTP JSON” 采集模块的应用。
获取开源项目概要信息
本教程提供的示例配置文件,采集的是 awx 的项目数据。将下载示例配置文件中的 add_gh_fields.json 和 filebeat.yml 复制到 Filebeat 的目录中 。
使用微软的 Virtual Studio Code 编辑器【或者其他的纯文本编辑器】打开 filebeat.yml 示例文件。查看该示例文件,你需要删除掉此文件中间的大部分内容「或者注释掉这部分先不用的代码」,只留下下面的剩余部分,用于做 Filebeat 的初始化测试。 你还需要使用上面的步骤中所准备好的 GitHub Personal Access Token 替换配置文件中第21行中 token 后面对应的参数。
###################### Filebeat Configuration Example #########################
# ============================== Filebeat inputs ===============================
filebeat.inputs:
# ============================== 建议先获取这一部分的数据 ===============================
# overall, contributors, releases, languages, tags 的数据少且重要,可以手工确认之后在做第二部分
# 获取项目的概要信息 - overall
# GET /repos/{owner}/{repo}
- type: httpjson
interval: 120m
config_version: 2
request.url: https://api.github.com/repos/ansible/awx
request.method: GET
# 在请求中增加个人认证令牌,提高数据获取条数限制
request.transforms:
- set:
target: header.Authorization
value: 'token ghp_Tx9xAbV7O6fuXYZ1234567890'
# 使用数据处理器,修整数据
processors:
# 优化分析:增加方便搜索分析的字段
- add_fields:
fields:
project: awx
kpi: overall
# 解码裸json结果:将 message 字段中的 json 内容解码为多个字段
- decode_json_fields:
fields: ["message"]
target: "json"
# ======================= Elasticsearch template setting =======================
# 配置索引模版基础属性
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 1
number_of_replicas: 0
index.mapping.total_fields.limit: 5000
setup.template.name: "filebeat"
setup.template.pattern: "filebeat-*"
setup.template.fields: "fields.yml"
# 修改部分 json 字段默认的数据类型
setup.template.json.enabled: true
setup.template.json.path: "add_gh_fields.json"
setup.template.json.name: "add_gh_fields"
# 禁用ilm功能
setup.ilm.enabled: false
# ================================== General ===================================
name: github-crawler
# ================================== Outputs ===================================
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
hosts: ["localhost:9200"]
index: "filebeat-7"
# ================================= Processors =================================
# 删除 Filebeeat 采集到的无关数据,节省存储空间
processors:
- drop_fields:
fields: ["ecs", "agent", "input", "host", "message"]
# ================================== Logging ===================================
logging.level: debug
# ============================= X-Pack Monitoring ==============================
# monitoring.enabled: true
以上配置文件仅使用了必要的参数选项,目的是实现开源项目概要参数信息的抓取,并测试 Filebeat 的可用性 (filebeat-7.17.0-darwin-x86_64.tar.gz 可以正常运行在 macOS M1 平台,Filebeat目前还没有 aarch64 的软件包 )。
不论是 macOS,Windows 还是 Linux ,打开命令行工具,进入 Filebeat 的解压缩目录后,执行下面的测试命令 ./filebeat test output。
➜ filebeat-7.17.0-darwin-x86_64 ./filebeat test output
elasticsearch: http://localhost:9200...
parse url... OK
connection...
parse host... OK
dns lookup... OK
addresses: ::1, 127.0.0.1
dial up... OK
TLS... WARN secure connection disabled
talk to server... OK
version: 7.17.0
以上返回结果表明:Filebeat 可以正常连接本机的 Elasticsearch 服务器。在Windows操作系统中,需要将 filebeat 可执行文件名换成 filebeat.exe ,后面的命令行参数不变。如果 filebeat.yml 配置文件的语法错误,这个命令中会报错。
理解 GitHub API 的限流和限速
使用 Filebeat 作为客户端访问 GitHub API 需要了解的重要信息都在官方文档上:点这里,下面都是一些必须理解的知识,以及有必要在运行 Filebeat 的操作系统上做的测试。
- 认证用户每小时的请求发送总配额是 5000 次;对于比较流行的项目而言,issue 或 pull request 两类的数据量比较多,很可能会用尽配额,建议使用 since 参数先拉取近期的数据分析,然后逐步拉取旧数据。
- 企业版用户的配额高一些,每个用户,每小时的配额是 15000 次。
- 未认证用户,每小时限制在60次请求。
- 建议在采集数据之前,先在 GitHub 上对目标项目进行大概的了解,预估 overall, contributors, releases, languages, tags,issues 和 pull request 等数据的条数和可能需要的请求次数,然后分步骤采集各类数据。
- 可以用加大 page size 参数 【per_page 参数的最大值为 100】的方式降低需要发出的请求次数。page size 越小,采集的项目数据量越大,越可能碰到被限流的情况。
检查你的 PAT 是否正确,或者用户是否被限流的方法是,在命令行里运行这条命令 curl -u martinliu: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 -I https://api.github.com/users/octocat ; 这个命令中 -u martinliu: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 包含了用户名和个人访问令牌(PAT)。
➜ curl -u martinliu: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 -I https://api.github.com/users/octocat
HTTP/2 200
server: GitHub.com
date: Thu, 17 Mar 2022 11:01:02 GMT
content-type: application/json; charset=utf-8
content-length: 1335
cache-control: private, max-age=60, s-maxage=60
vary: Accept, Authorization, Cookie, X-GitHub-OTP
etag: "c9c3cea653b1e722852a41f65a43a5e969c0722c81525b3f1a27f7678269c6ba"
last-modified: Tue, 22 Feb 2022 15:07:13 GMT
x-oauth-scopes: public_repo, repo:status
x-accepted-oauth-scopes:
github-authentication-token-expiration: 2022-04-15 06:47:45 UTC
x-github-media-type: github.v3; format=json
x-ratelimit-limit: 5000
x-ratelimit-remaining: 4440
x-ratelimit-reset: 1647516784
x-ratelimit-used: 560
x-ratelimit-resource: core
access-control-expose-headers: ETag, Link, Location, Retry-After, X-GitHub-OTP, X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Used, X-RateLimit-Resource, X-RateLimit-Reset, X-OAuth-Scopes, X-Accepted-OAuth-Scopes, X-Poll-Interval, X-GitHub-Media-Type, X-GitHub-SSO, X-GitHub-Request-Id, Deprecation, Sunset
access-control-allow-origin: *
strict-transport-security: max-age=31536000; includeSubdomains; preload
x-frame-options: deny
x-content-type-options: nosniff
x-xss-protection: 0
referrer-policy: origin-when-cross-origin, strict-origin-when-cross-origin
content-security-policy: default-src 'none'
vary: Accept-Encoding, Accept, X-Requested-With
x-github-request-id: 4664:4A3B:121A47C:12EB215:623314EE
以上结果表明了,认证成功的 GitHub 账号,且未被限流的桩体,结果中的这几个参数最重要:
* x-ratelimit-limit: 是 5000 表明用户名和PAT是正确的,如果是 60 表明,这个用户名和token组合错误,未认证用户的限制是 60。
* x-ratelimit-remaining: 4440 当前这个小时里的剩余API请求数。
* x-ratelimit-reset: 1647516784 下一次访问限制被重置的时间。
在采集数据之前,确认能看到类似于以上的数据,否则不要继续做下面的步骤。
基于 GitHub API 使用的限流特性,建议分类,分时段采集数据,避免发生被限流的状况。
在使用 Filebeat 的 HTTP JSON 模块采集 GitHub API 数据的过程中很难不会碰到被限流的情况(请求),在被限流的时候,你可以在 filebeat 的滚动日志中看到类似下面的信息。
2022-03-17T11:22:53.262+0800 ERROR [input.httpjson-stateless] v2/input.go:115 Error while processing http request: failed to execute http client.Do: server responded with status code 403: {"message":"Resource protected by organization SAML enforcement. You must grant your Personal Access token access to this organization.","documentation_url":"https://docs.github.com/articles/authenticating-to-a-github-organization-with-saml-single-sign-on/"} {"id": "BF2B0C218CAC3BA0", "input_url": "https://api.github.com/repos/elastic/beats/releases"}
以上信息表明,你当前的账户访问被限流了,这样你不得不等待一个小时后,在让 Filebeat 继续采集数据。
自查点
下一步开始进行数据初始化前的准备基础准备工作。
采集并确认部分项目数据
在导入数据之前,需要完成下面这几项任务:
- 导入为大家准备好的 Kibana 配置文件。
- 在配置文件中只开启 overall 部分的数据采集
- 首次启动 Filebeat ,并停止它
- 在 Kibana 中确认采集到的数据
- 为了大批量数据采集,修改索引字段数量上限
下面详细讲解操作过程。
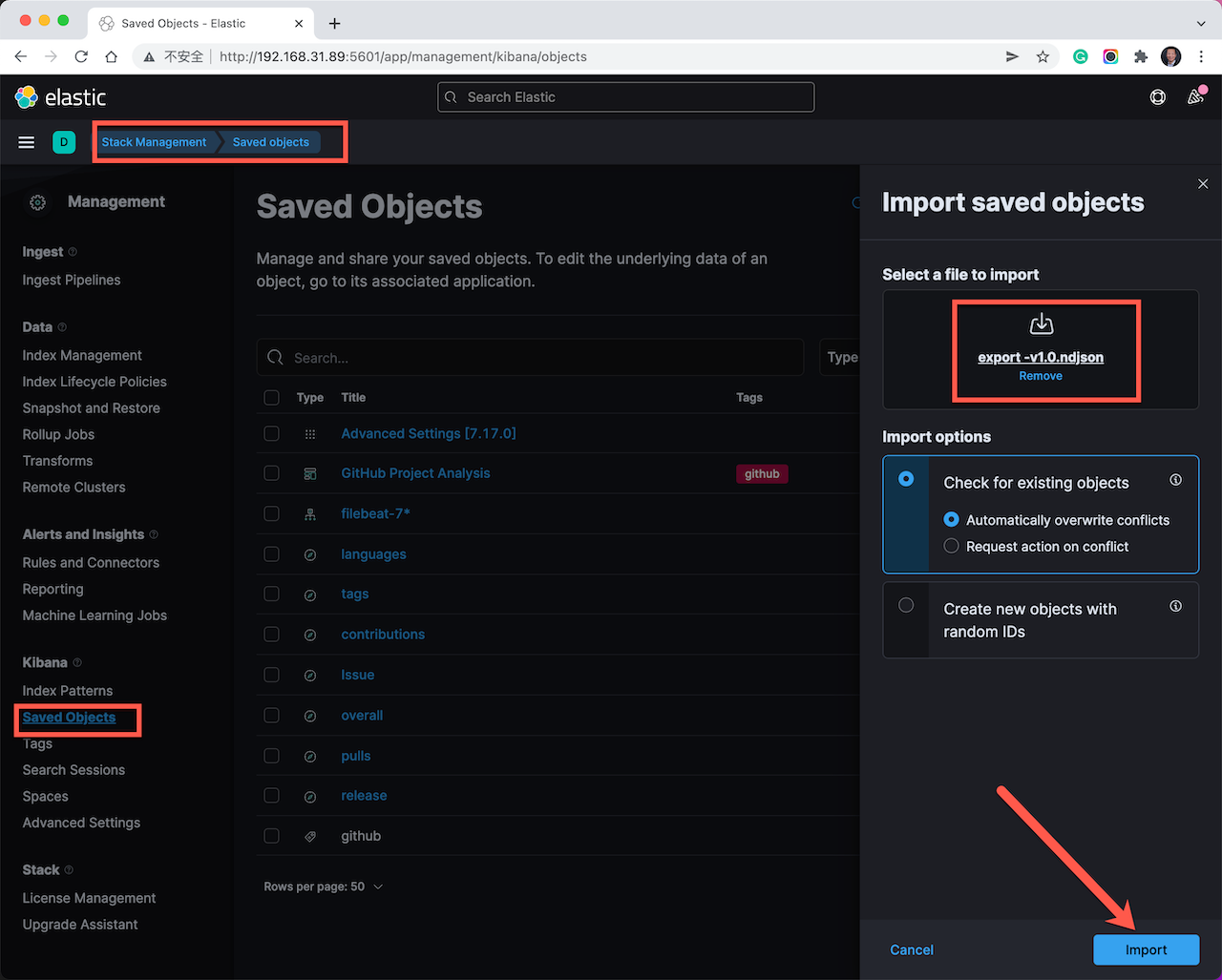
在解压缩后的 zip 文件中,找到 export-v1.0.ndjson 文件;在浏览器中打开 Kibana 的界面,点击左侧菜单:需要导入示例 Kibana 可视化对象。
点击展开左侧菜单,选择: Management –> Stack Management –> Kibana –> Saved Objects –> 点击右上角的 “Import” 按钮,选中 “export-v1.0.ndjson” 文件,点击右下角的导入按钮。
用文本编辑器打开 filebeat.yml 配置文件,确保在 filebeat.inputs: 这个部分中只包含下面的采集项目概况的代码。
- type: httpjson
interval: 6m
config_version: 2
request.url: https://api.github.com/repos/ansible/awx
request.method: GET
# 在请求中增加个人认证令牌,提高数据获取条数限制
request.transforms:
- set:
target: header.Authorization
value: 'token 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' #此处的token示例需要被替换
# 使用数据处理器,修整数据
processors:
# 优化分析:增加方便搜索分析的字段
- add_fields:
fields:
project: awx
kpi: overall
# 解码裸json结果:json 内容解码为多个字段
- decode_json_fields:
fields: ["message"]
target: "json"
以上代码中 token 后面的字符串需要替换为你自己的,获取方式参考前文。
重点解释几个参数:
- type: httpjson : 这是使用 Filebeat 的 httpjson 采集模块,下面整段都是它的配置,每一段采集一个不同的 GitHub API。
- intervel:6m : 配置这个采集条目的采集频率,如果该类型数据变化频率不高,每天采集两三次即可。60m 是 60 分钟采集一次的频率,可以配置为 60 分钟的 n 倍,GitHub API 限流的周期也是按 60 分钟恢复一次的。数据量大的时候需要考虑延长采集间隔,取保一个周期内,可以将所有数据都刷新一遍。
- request.url: 这里配置的是不同 GitHub API 的路径,其中包括了目标分析代码库的全路径,需要在采集前用浏览器测试其正确性。如果考虑到采集可能受限制,可以查阅 API 文档,适当提高 page size 的大小,从而节省采集请求次数。
- request.transforms: 配置了使用 token 认证方式,保证 filebeat 使用你的个人访问令牌,以认证用户的身份采集数据,否则非认证用户 60 次的请求限制,分分钟就会被用完。
- add_fields: 这一段配置了开源项目的名称和数据分类;这里使用了手工配置的方式,在后续增加其它类型数据采集的时候,你需要确认修改 project: 字段的项目名称,分类名称和 request.url 对应,不需要修改。
打开命令行工具,进入 Filebeat 解压缩后的目录中。运行下面的命令 ./filebeat -e。
➜ filebeat-7.17.0-darwin-x86_64 ./filebeat -e
这条命令的输出日志应该很快就会停止。 按 ctrl + c 结束首次数据采集测试。在没有报错的情况下,初始化信息采集就成功了。下面开始在 Kibana 里确认数据采集结果。
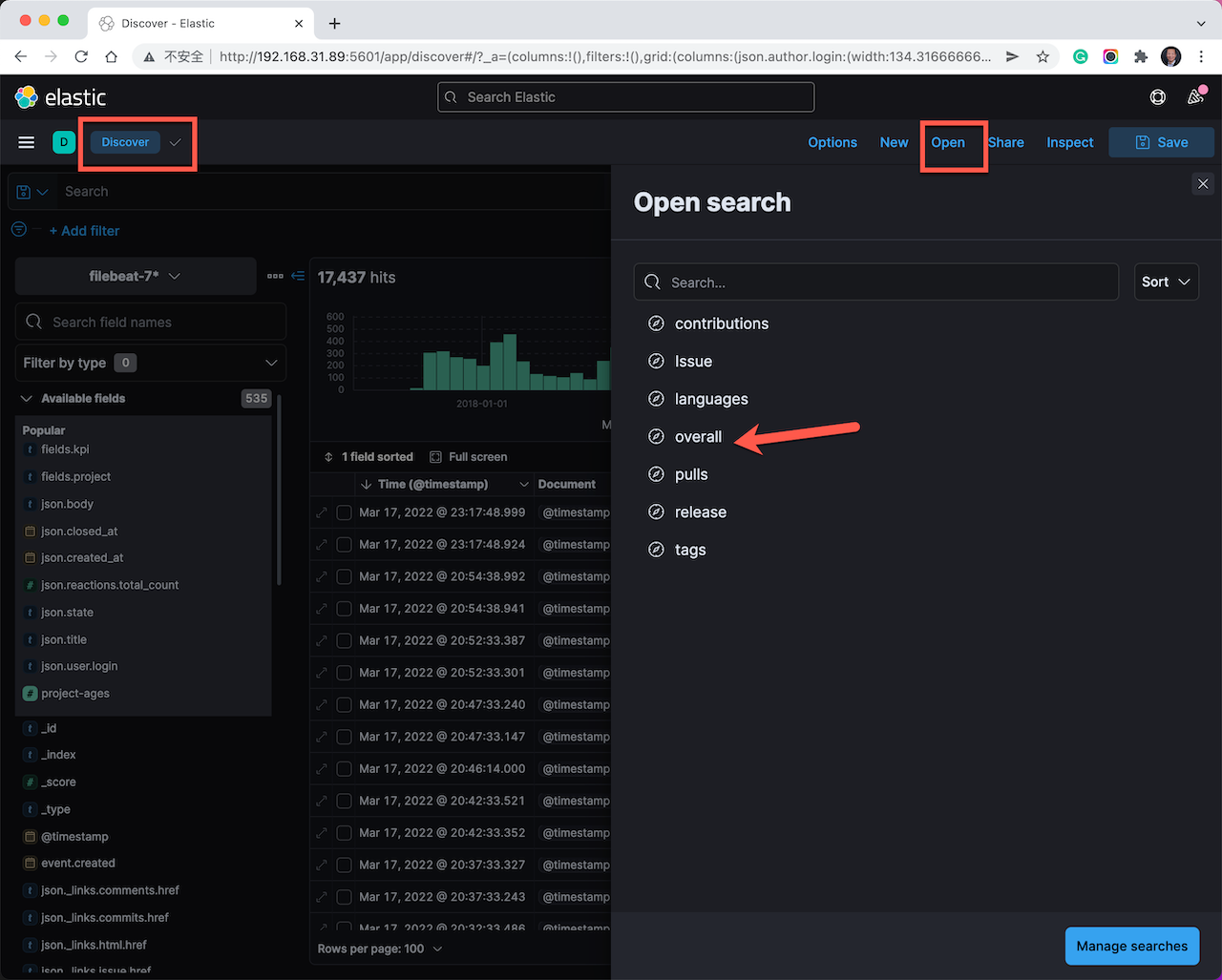
点击 Kibana 左侧菜单:选择: Analytics –> Discovery –> 右上角的 Open 菜单 –> 选择 overall 预制查询视图。在数据显示视图中,至少应该有一条数据,打开这条数据观察所有采集到的字段。项目 Overall 的数据信息丰富,变化率不大,可以每天两三次,就能够绘制出相关的趋势分析图表。
虽然只采集到有限的项目概况数据,现在已经可以查看 GitHub 开源项目分析看板的样貌了。
点击 Kibana 左侧菜单:选择: Analytics –> Dashboard –> 点击 GitHub Project Analysis 。
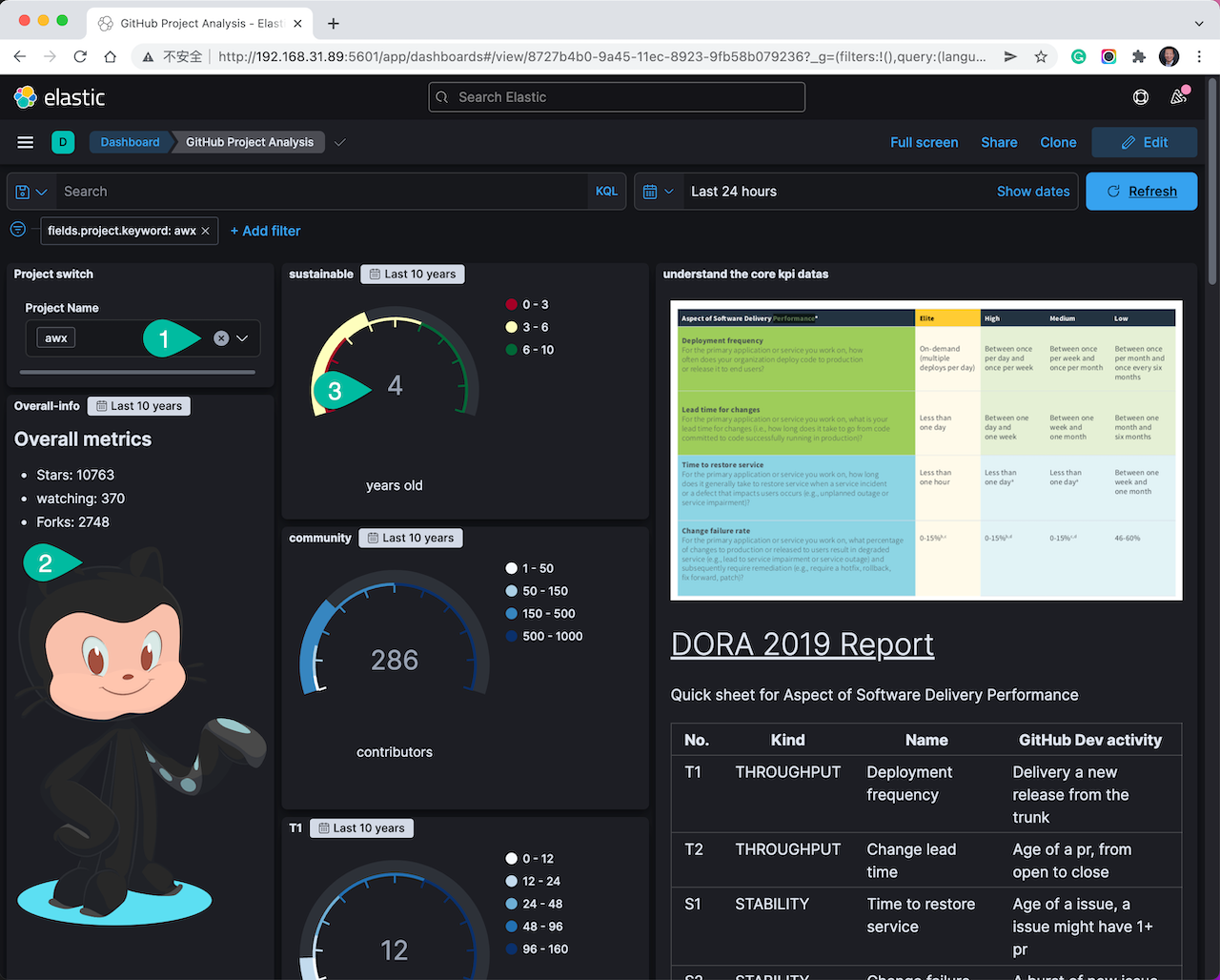
查看相关信息点:
- 在项目选择菜单中,选中 filebeat.yml 文件中所配置的项目名称。界面中的数据会自动刷新。
- 在 overall mertrics 这个区域里显示了基础的项目数据。
- 这里显示了项目的年龄。这是个扩展字段,如果没有显示正确数值的话,应该排查解决后,在进行后续的采集和分析。
在我们分析一个开源项目的时候,完全不能只看 overall metrics 中的概况基础数据。可以参考 DORA 2019 Report 的分析报告,点击那个链接打开相关的说明文档。这是一个长期的跟踪调查,从四个维度分析软件交付效能。我将每个分析维度和 GitHub 中的相关开发活动数据做了对应。
| No. | 类型 | 名称 | GitHub 对应的开发活动数据 |
|---|---|---|---|
| T1 | 吞吐量 | 部署(发布)频率 | 从主干交付一个正式发布版本,观察 GitHub 上项目 release 的频次,反应了产品的整体推进速率 |
| T2 | 吞吐量 | 变更前置时间 | 任一 Pull Request 都包含修改、评审和合并的过程,度量 pr 从创建到关闭的周期,就可以看出代码参与各方的协作效率 |
| S1 | 稳定性 | 服务恢复时间 | issues 很可能对应这用户环境(线上服务)的问题。任一 issues 的解决都可能关联 0 ~ n 个 pr,分析 issues 从创建到关闭的时间周期,能分析出该项目的问题处理能力 |
| S2 | 稳定性 | Change failure rate | 失败的版本发布或者代码修复(pr)都会导致 issues 的扎堆创建,可以观察在新的 release 之后,或者一波 PR 关闭之后,有没有发生 issues 数量剧增的情况 |
在项目分析数据集看板的不同模块的标题中,我使用到了 T1、T2 和 S1 的标签,其它周围的数据分析块也同时起到了参考支撑作用。
值得说明的是,这四个维度的正向和反向分析都是值得推敲的,可以会推导出完全相反的结论,需要理性判断。例如:某个代码库长期以来,保持着很高的 open issues 的状态,open issue 的数量高达 1500 以上。这个数据可能的分析方向如下:
- 它是非常火爆的项目:遭到用户热捧,参与者积极踊跃的参与项目反馈。
- 项目技术债的坑很深:用户对这个坑很多,坑很深的项目,保持着忍耐且不离不弃,并长期吐槽的状态。
- 项目核心开发团队(含外部贡献者)专注于创新:项目参与各方无法协同平衡新功能开发和技术债清理之间的矛盾,而开发新功能的诱惑往往更大,大家就默认选择了前者。
- 项目的原作者/公司转战其它赛道:项目原作者团队是持续性的主要负责方,解铃还须系铃人,外部贡献者和其它开发者很难接盘或者挽救这样的项目。
希望以上各种假设开阔了你分析开源项目的思路,而应该选择那个分析结论,还依赖于你对这个项目其它背景信息,和历史发展过程的了解程度。
可以在 Kibana 的时间选择控件中,选择最近三个月、半年、一年等时段进行特定的分析,也可以选择过去的某一年或者半年做 YOY 的年度对比分析。特别是对 release、pr 和 issues 三类数据的综合分析,我们不难从开发效能的角度度量这些开源项目的整体研发效能实力。本教程为大家抓取和分析数据提供了技术工具的支撑。为你进行项目的深度分析提供基础的信息和角度。根据不同的项目分析需求,我们从这些数据中还可以开发出其它各种分析角度和图表。我为此在 GitHub 上也创建了一个项目,欢迎大家一起交流。
项目地址: https://github.com/martinliu/sdp-dashboard
在进入大批量数据采集前,还需要微调 Elasticsearch 后台的索引字段数量上限。点击展开左侧菜单,选择: Management –> Dev Tools –> Console。 在这个开发者工具的左侧输入并执行下面的代码。
PUT filebeat-7/_settings
{
"index.mapping.total_fields.limit": 5000
}
执行的结果如下图所示。
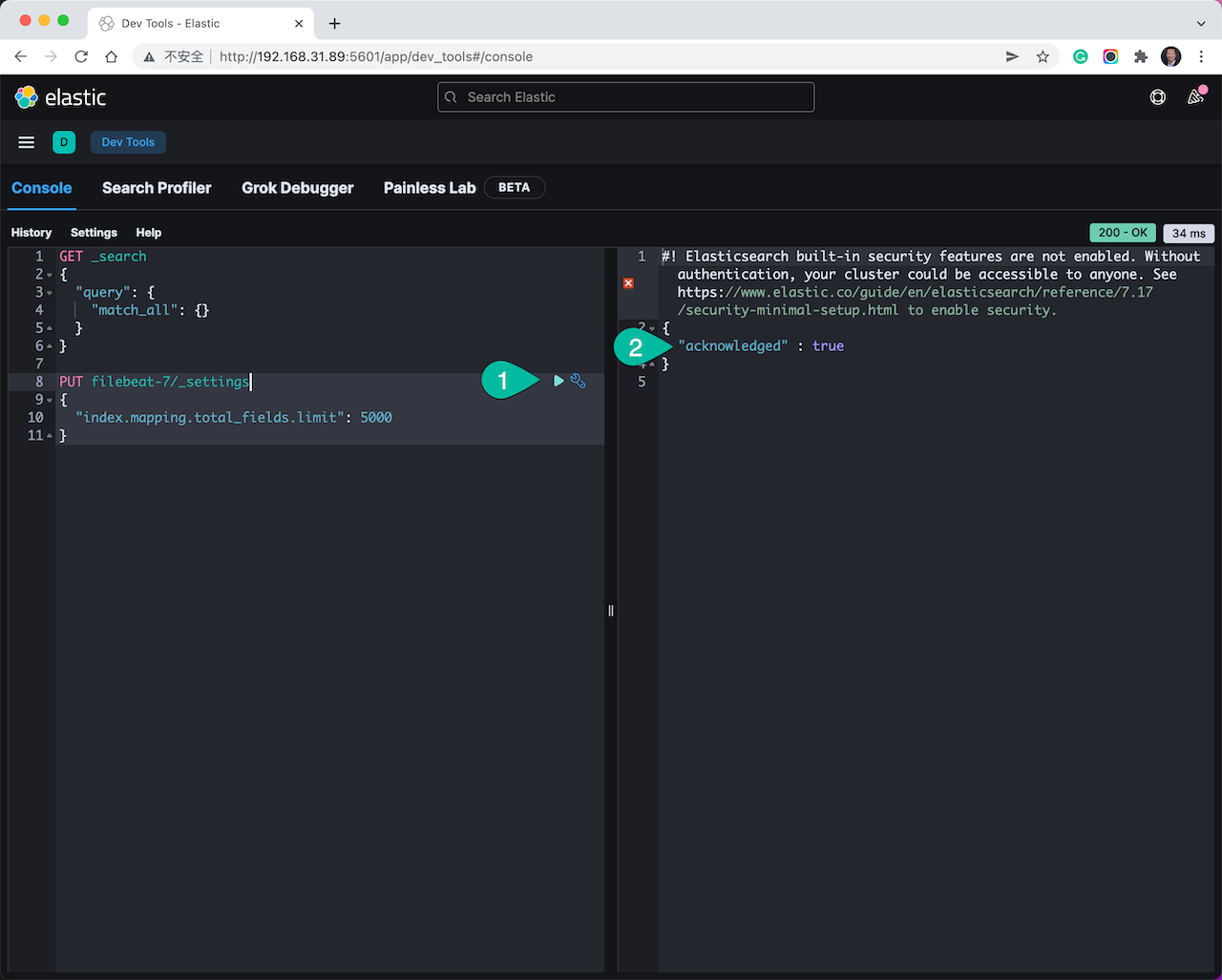
操作步骤:
- 粘贴入以上代码后,点击右三角的执行按钮。
- 右侧结果返回为: true ,表明成功更新了索引配置。
自查点
在以上自测点都成功以后,再进入下面的步骤。
分类采集项目其它数据
在成功采集了项目概况数据以后,我们接下逐步采集和分析其它类型的数据包括,但不限于下列数据:
- contributors: 此 API 会按贡献值倒序的方式返回贡献者清单,数据条数不一定完整,但是我们最多能关注前 30 的贡献者,排名靠后的大量贡献者,都是非活动的,贡献次数为10 以内的非关键人员。很可能这个清单是无法访问的,项目所属公司对其限制了访问权限。其他 API 也可能有这个问题。
- releases : 关键重要指标数据,但是不是所有项目都很专业的从一开始就维护 reelase 清单,有些项目会记录每个 release 的下载次数和点赞互动次数,有些项目不跟踪下载次数。
- languages : 非关键重要数据。
- tags : 分关键重要数据
- issues : 极其关键且重要数据,对于比较火热的项目数量比较大,多则几万条。
- pulls: pull rquest 也是极其关键且重要数据,值得深度分析。火热项目数据量较大。
顶级开源项目的全量数据文档数会比较轻易的超过 5 万条。
参考下面的步骤采集以上每一类数据:
- 从示例 filebeat.yml 配置文件中,复制一段目标的配置参数段落,粘贴到测试机的 Filebeat 配置文件中。
- 修改 request.url , token 和 fields.project 等关键字段。
- 在浏览器中再次确认修改后的 request.url 是否能正常访问,排除 GitHub 网站服务不好的情况。或者在命令行里使用 curl 命令测试。
- 运行
./filebeat test output测试后端 Elasticsearch 服务器的服务是否正常。 - 运行
./filebeat -e开始当前这个新分类的数据采集 - 等待命令行日志停止滚动,除了 issues 和 pulls 之外,其它分类数据,应该在分钟级别的就可以完成首次采集。对于数据量大的项目,issues 和 pulls 都可能会耗时一小时,或者更长时间。
- filebeat 采集的滚动日志在命令行里静止的时候, 按
ctrl + c结束数据采集。 - 在 Kibana 中,进入 Discovery ,点击 open 菜单,选中对应的查询视图;可能需要先调整一下时间控件的时间设置,例如选择最近一年,观察数据在时间上的分布,观察采集到了多少条该类数据,将采集到的文档数与在 GitHub 上该项目页面上的数据做比对确认。也很可能需要多个采集周期才能追平这类数据的条数。
- 打开单个文档,观察和熟悉这类数据都有那些字段,思考还有那些是值得分析的字段,可以将其添加到当前的数据表格中;对于 issues 和 pull 数据文档,还需要观察
project-age这个实时计算字段的数值,它是一个以分钟为单位的计时器,issue 和 pull rquest 的状态为 closed 后就不会变化。 - 尝试用右上角的时间选择控件改变时间分析区间,观察其他时间分析区间的数据分布特性和数值。
- 返回 Dashboard –> GitHub Project Analysis 开源项目分析看板,查看相关类别数据的分析图表,也可能需要微调某数据显示控件。选择不同的时间跨度,浏览项目数据的完整性。有些项目概况数据是保持不变的。
仔细的重复以上 11 个步骤若干次,知道你认为目标分析项目的所有必要数据都已经抓取到 Elasticsearch 中了。如果在这个过程中发生了误操作,或者需要换其它项目重新分析。你可能会使用在 Dev Tools 中使用到下面的这些命令。
# 查看索引中的文档总数
GET filebeat-7/_count
# 删除索引
DELETE filebeat-7
# 删除导入的扩展字段
DELETE _template/add_gh_fields
你可以随时检查文档总数,判断数据下载的进度。在有必要删除所有数据重新开始的时候,执行删除索引和模板两个操作。如果你访问 GitHub 的网络条件有限,网页打开都比较卡的话,这个数据采集的过程可能会比你想象的长。顺利的话,新手也应该在两三个小时内完成数据采集。
定制项目数据分析看板
如果你已经成功的完成了以上所有操作步骤,你的目标项目数据采集也是基本完整的,你将看到一个类似于下面的数据分析面板。
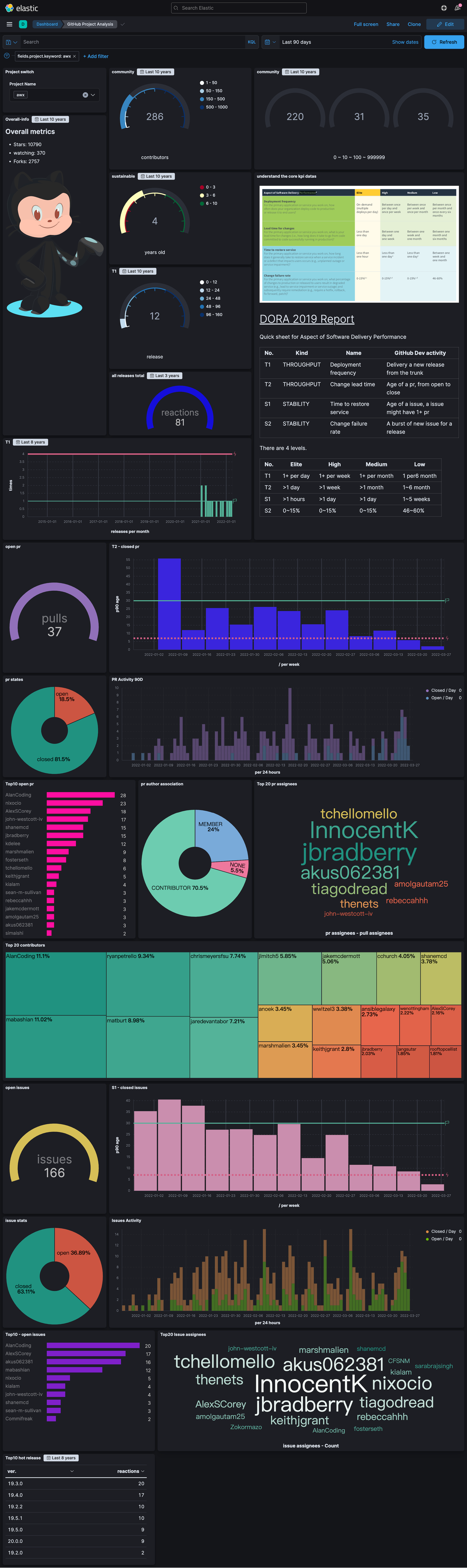
修订示例数据显示控件
想要修改某个数据显示控件,可以点击它右上角的齿轮按钮,打开控件编辑菜单选中 “Edit Visualization” 选项,进入修订编辑模式。如果你想同时保持着它,可以选择 “clone panel” 选项,在克隆的新的控件上修订。
下面是数据显示控件的修订状态。
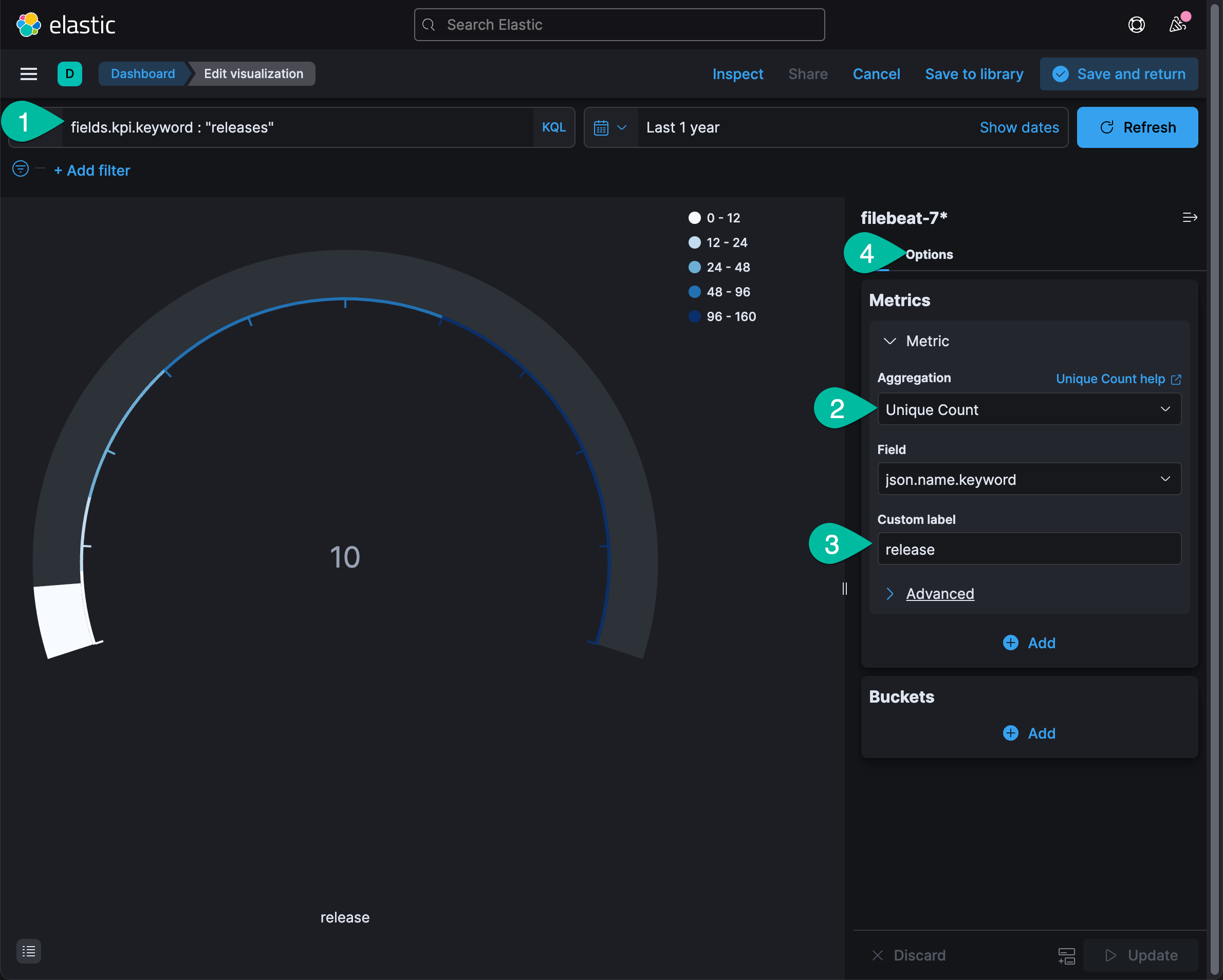
操作步骤参考说明:
- 修改数据查询条件
- 选择数据分析算法
- 修改控件标签
- 点击 Optioins 后进入图例修订界面
还可以点击日期选择控件查看不同时间条件下的数据分析结果。修订满意后,点击右上角的 “save and return” 按钮。
用 Lens 创建新数据分析
Kibana 中的 Lens 功能是非常方便易用的数据分析工具,在 Dashboard 界面中,点击左上角的 “Create visualization” 按钮默认就进入了这个分析工具。如下图所示。
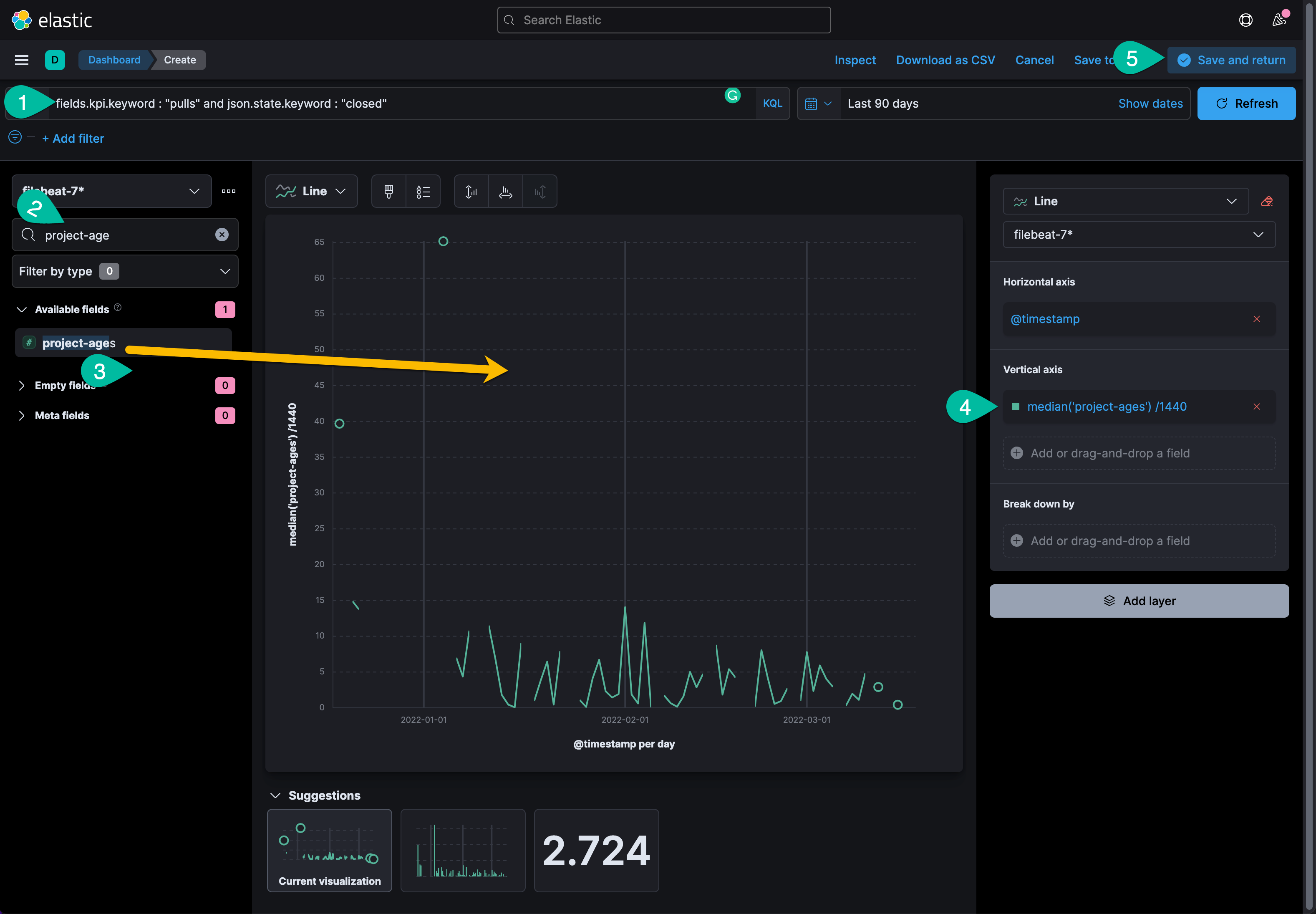
示例操作说明:
- 配置数据搜索条件:90 天里的所有关闭 pull request 数据。
- 搜索目标分析字段:project-age
- 用鼠标将这个字段拖拽到右侧的空白处。Lens 会智能的推荐数据显示模式。点击上方的图形模式下拉菜单,或者从推荐的模式中选择显示效果,锁定目标的数据可视化显示模式。
- 点击竖坐标的数据分析算法,调整数值统计方法。
- 分析操作完成之后,点击 ”save and return“ 按钮,返回 Dashboard,用鼠标拖拽这个控件的边框,改变它的大小和形状,还可以将其拖拽到合适的位置,与其它数据形成对照和参考的关系。
Kibana 的数据分析功能比较简单易用,但是它的功能比较多,学习提升空间很大。如果你制作了新的数据分析控件,欢迎将你的控件导出后分享给其他人。请提交到我的这个 GitHub 项目中https://github.com/martinliu/sdp-dashboard.git,或者发邮件给我 [email protected] 。
总结
我们通过本教程学会了 Elastic Stack 的一个典型的应用场景,包含数据摄入和分析的全过程。如果你还想将这个分析结果分享给其他人,或者公司的同事。 你可以在一台云主机上完成以上所有操作,然后将 Kibana 的访问地址分享给其它人。